Prometheus 告警
Prometheus 告警
# 邮件(Grafana)
Grafana Alerting支持多种告警渠道,比如钉钉,Discord,Email,Kafka,Pushover,Telegram,WebHook等等,我们这里可以使用Email进行展示
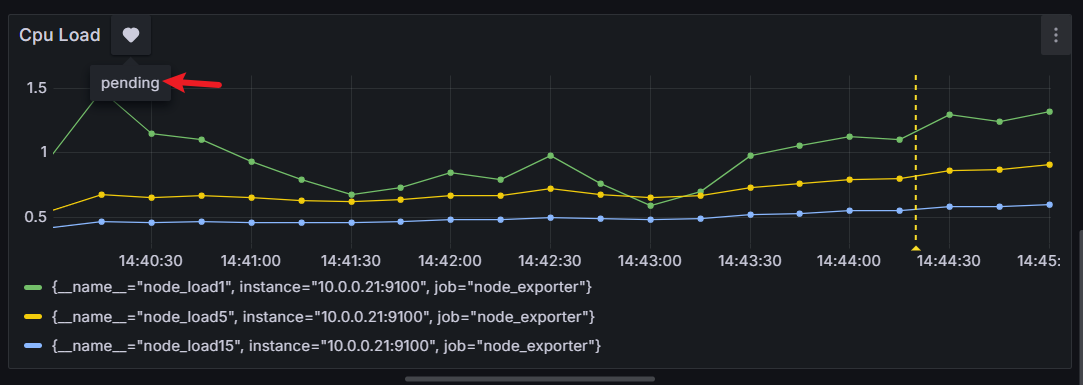
1.开启告警配置
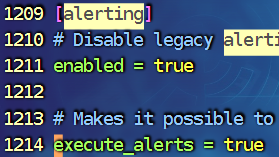
Email是我们最常见的告警接入方式,通过Grafana告警需要在Grafana的配置文件中配饰SMTP服务,在配置/etc/grafana/grafana.ini中,大概在626行,开启告警 820行左右(直接用 / 查找)
 重启Grafana:systemctl restart grafana-server.service
重启Grafana:systemctl restart grafana-server.service
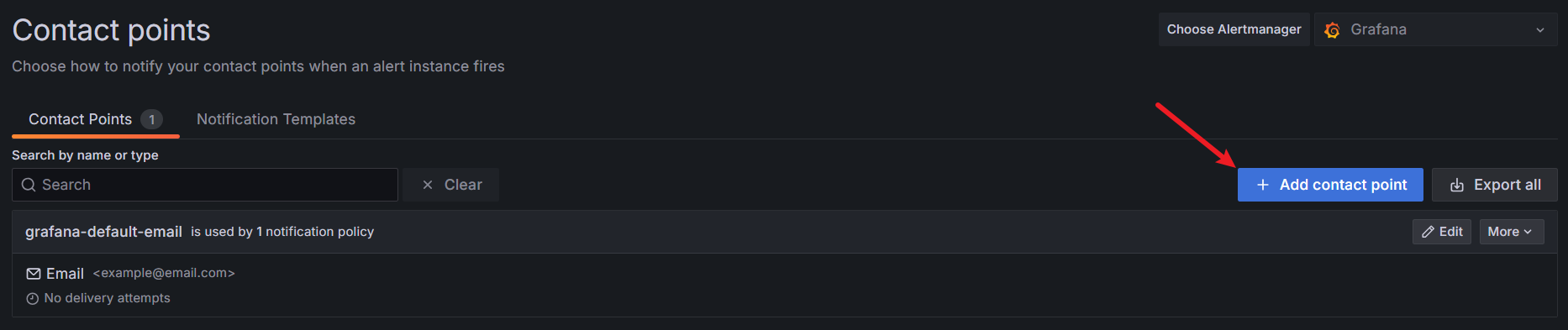
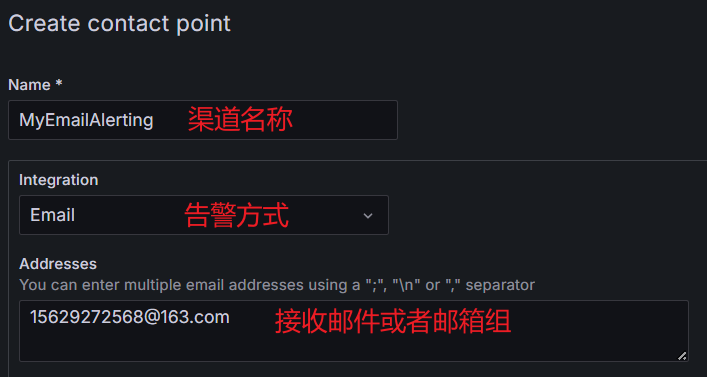
2.配置通知渠道(邮件接收者)
在不同版本的 Grafana 中这里可能叫法不同
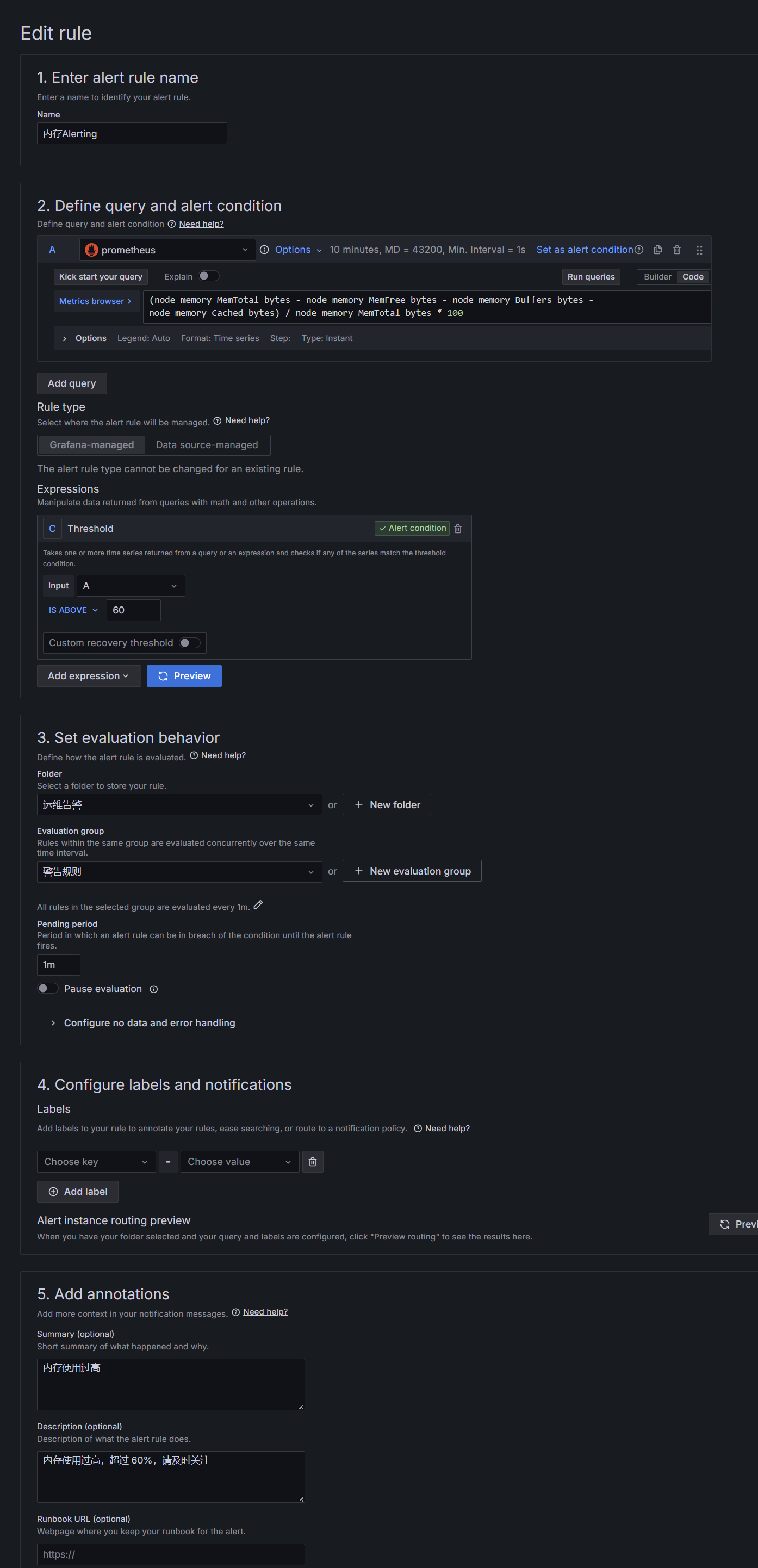
 3.添加报警规则
3.添加报警规则
但是这里面我们要注意,它并不能识别我们的查询语句中的变量:host,interval 等的信息,那遇到这种情况我们怎么办呢,我们可以复制一条语句然后在下面创建一个新的查询(不用于展示)
两点需要注意:
- 新建的查询语句不展示在Panel上
- 查询语句必须是固定的参数,不能是变量
另外,也可以直接去 Dashboard 内创建报警
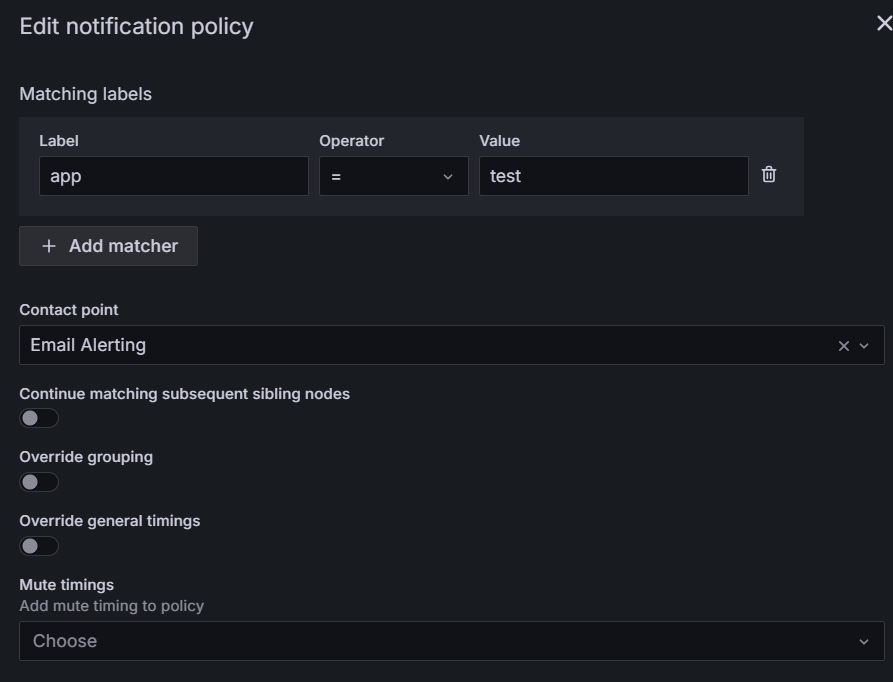
4.设置 Notification policies(报警匹配规则)
因为 alert rule(报警规则) 是通过 label 来匹配 contact point(通知策略)
所以需要定义一个 Notification policy,给 contact point 定义 label
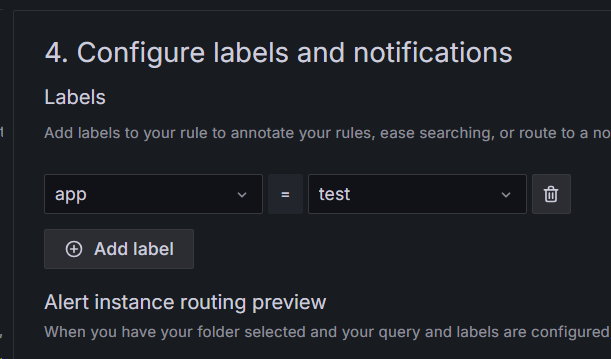
 5.给 alert rules 设置 lable,绑定通知方式
5.给 alert rules 设置 lable,绑定通知方式
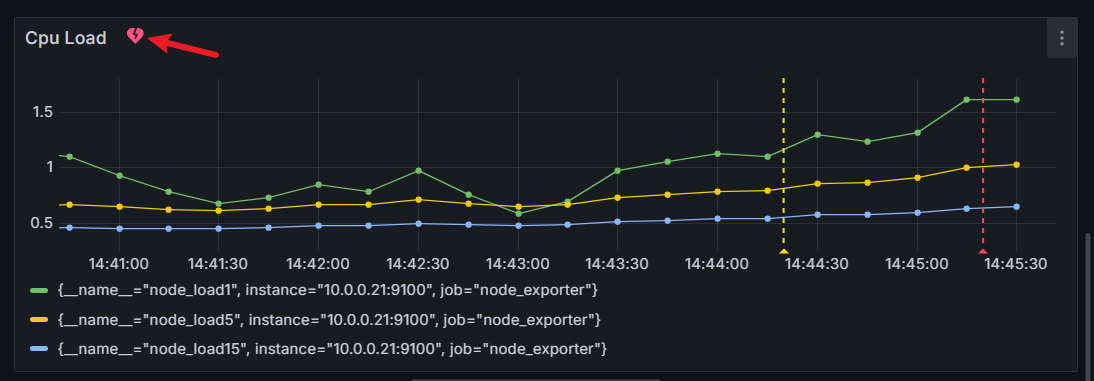
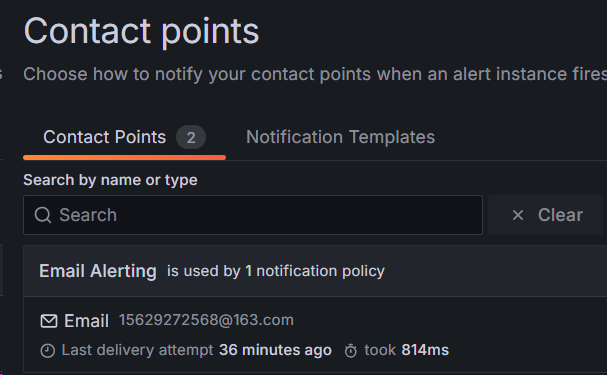
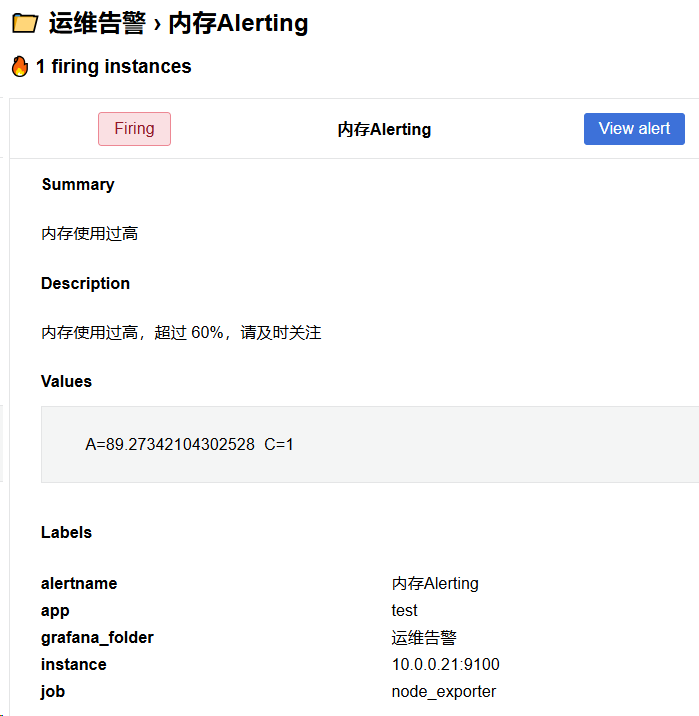
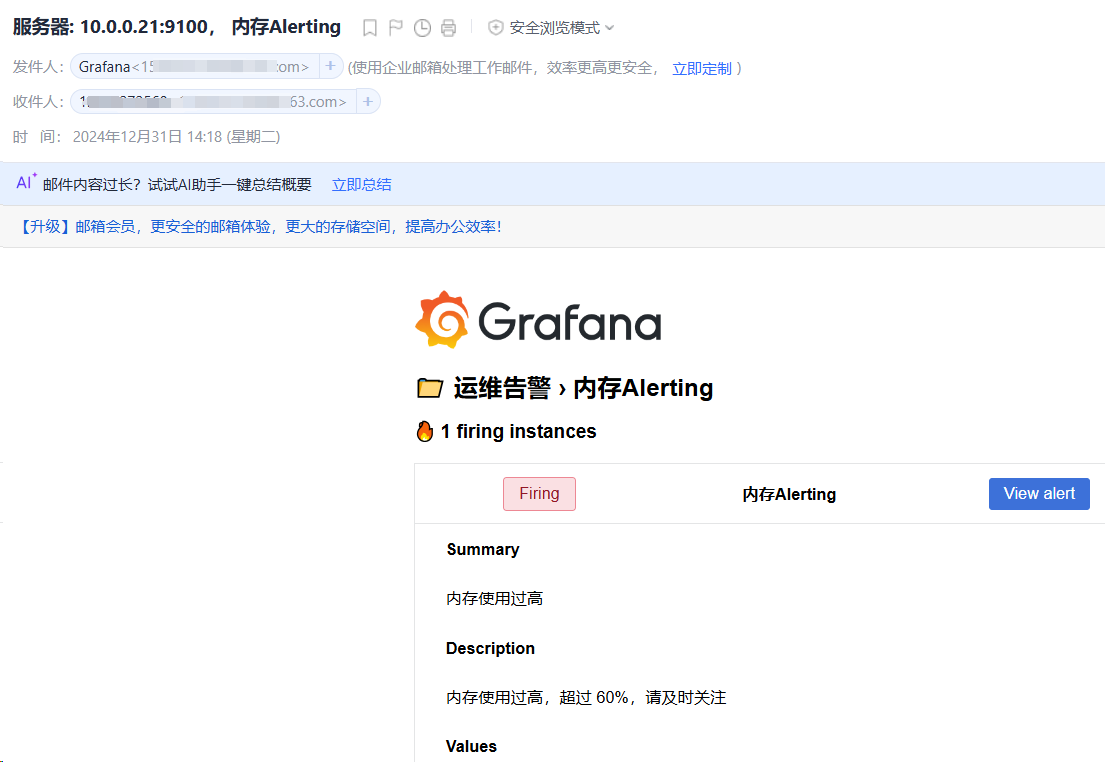
 接下来对内存进行压测,观察邮件发送
接下来对内存进行压测,观察邮件发送
dd if=/dev/zero of=/dev/null bs=1G count=102400

# 多序列
我们经常在监控报警的查询中会返回多个序列,Grafana 的报警中的聚合函数和阈值检测都会去评估每一个序列,但是在 Grafana 目前不会去跟踪每个序列的报警规则状态,所以这会影响到我们的报警结果
具体过程:
1.报警返回两个序列 server_1和server_2
2.server_1触发了报警规则并切换到了报警状态
3.发送消息通知出去,比如发送的消息是:负载达到了80%(server_1)
4.如果在同一报警规则的后续评估中,server_2序列也会导致触发了报警
5.这个时候不会发送新的通知,因为报警规则已经处于报警状态之下了
2
3
4
5
所以从上面的场景可以看出,如果规则处于告警状态了,当其序列也达到了报警条件后,Grafana不会发送消息通知,目前Grafana官方有针对多个序列查询的支持,会在未来的版本中跟踪每一个序列的状态,所以目前也是Grafana功能的一个局限性
# 告警模板
就是一个可以传进来的变量
# PushGateway
我们都知道 Prometheus 采集数据使用的是pull的方式,但是在某些网络下(不在一个子网或者防火墙),Prometheus无法直接拉取监控指标数据,这个时候我们就需要一个和能够主动push的模式了,而PushGateway就是Prometheus生态中来解决这个问题的一个 工具
但是把PushGateway也不是万能的,其本身也存在一些弊端
- 将多个节点数据汇聚到pushgateway,如果pushgateway挂了,会收到很大范围的影响
- Prometheus拉取状态up只针对pushgateway无法做到对每个目标有效
由于 pushgateway 可以持久化推送给它所有监控数据,所以即使你的监控已下线,Prometheus还会拉取到旧的监控数据,需要手动清理Pushgateway不要的数据
下载后启动一下
 Pushgateway的数据推送支持两种方式:Prometheus Client SDK推送和API推送
Pushgateway的数据推送支持两种方式:Prometheus Client SDK推送和API推送
Client SDK 推送
Prometheus本身其实支持了多种语言的SDK,可通过SDK的方式生成相关的数据,并推送到Pushgateway,当然了这种方式需要客户端代码支持,这也是官方推荐的方案,目前SDK支持的语言:Go、Java or Scala、Python、Ruby、Rust
当然也有许多的第三方库,详情参考:https://prometheus.io/docs/instrumenting/clientlibs
这里我们可以使用Python为例,因为我这里是Python3,所以需要使用pip3 安装一下 prometheus的sdk开发包
pip3 install prometheus-client -i "https://mirrors.aliyun.com/pypi/simple"
如果有公钥验证:pip3 install prometheus-client --trusted-host mirrors.aliyun.com -i "http://mirrors.aliyun.com/pypi/simple"
SDK 示例
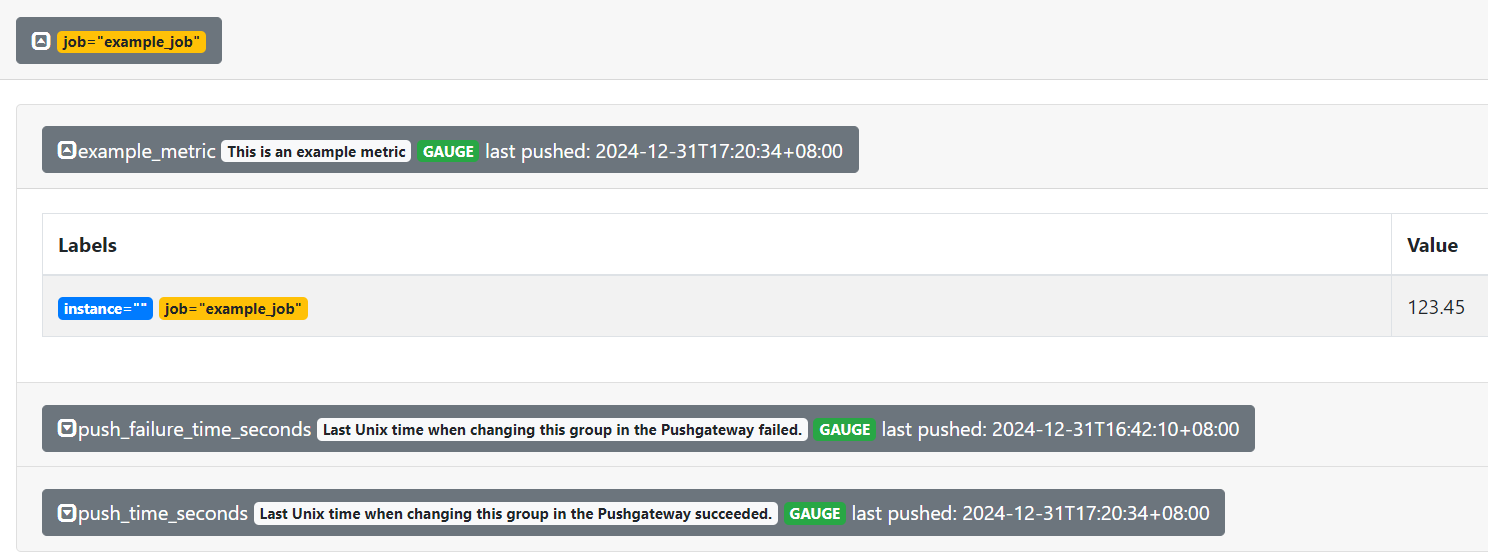
from prometheus_client import CollectorRegistry, Gauge, push_to_gateway
# 创建一个指标注册表
registry = CollectorRegistry()
# 创建一个 Gauge 指标
g = Gauge('example_metric', 'This is an example metric', registry=registry)
# 设置指标的值
g.set(123.45)
# 推送到 Pushgateway
push_to_gateway('http://localhost:9091', job='example_job', registry=registry)
print("Metric pushed successfully!")
2
3
4
5
6
7
8
9
10
运行 python 代码,观察 alertgateway 控制台
API 推送
还可以使用Prometheus文本协议推送指标,无需借助单独的CLI,只需要curl之类的工具即可。不过需要注意的是文本中必须包含("LF"或者"\n")来结尾,以其他方式结束一行,例如:"CR" ('r'),'CRLF' ('\r\n')或者只是数据包结尾,将导致协议错误
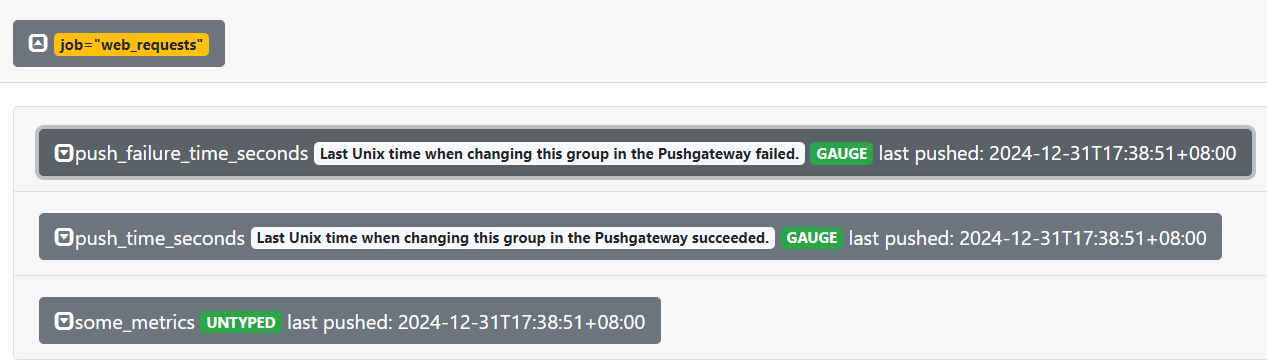
echo "some_metrics 3.14" | curl --data-binary @- http://10.0.0.21:9091/metrics/job/web_requests
这里是将数据样本推送到了job名为web_requests的标识组中
接下来我们推送一个更麻烦点的
cat <<EOF | curl --data-binary @- http://10.0.0.21:9091/metrics/job/web_requests/instance/web
# TYPE some_metric counter
some_metrics{label="vall"} 22
# TYPE another_metric gauge
# HELP another_metric Just an example.
another_metric 2991.132
EOF
2
3
4
5
6
7
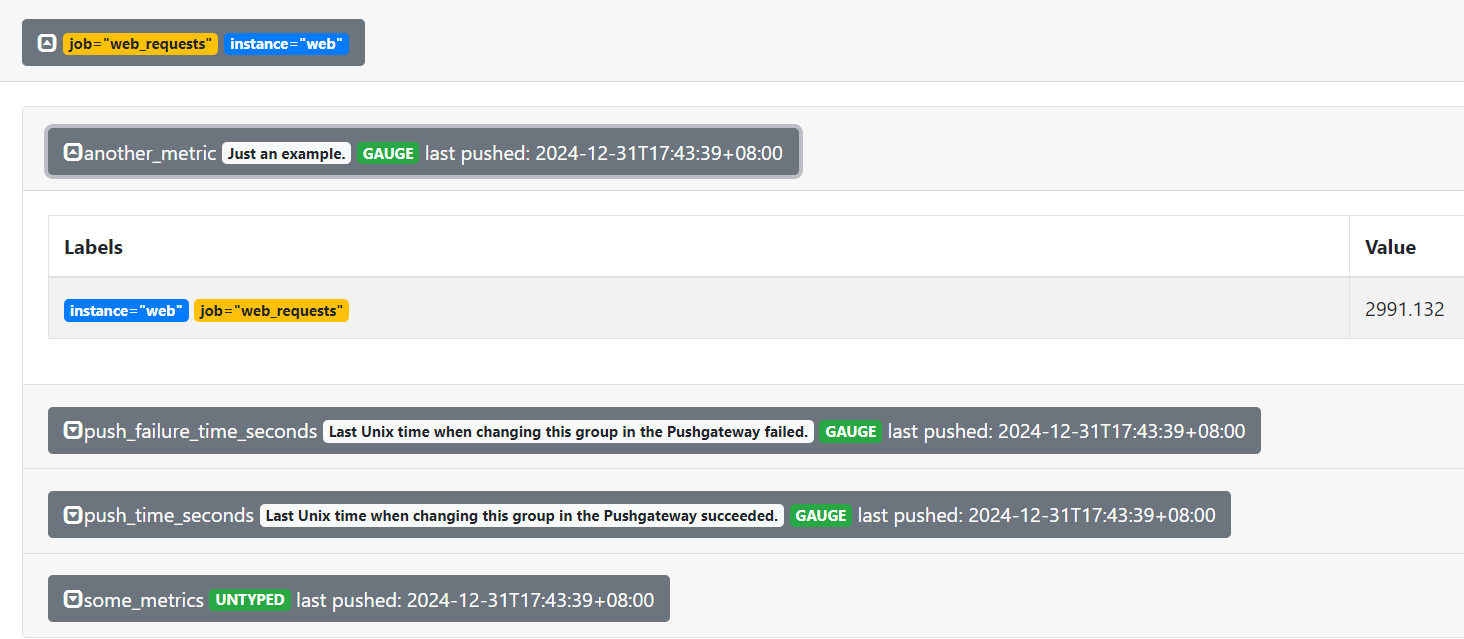
可以看到,虽然是同一个job但是instance是不同的,这个时候他们的数据是不在一起展示的
删除指标也非常的简单,这个时候就使用到我们的HTTP 协议中的DELETE了,我们来删除刚刚创建的一个分组
curl -X DELETE http://10.0.0.21:9091/metrics/job/web_requests/instance/web
需要注意的是,这里的删除是根据分组标识进行删除的比如删除{job="web_requests"}下的所有指标
抓取目标
修改 prometheus 的配置文件,发现服务,随后重启 prometheus
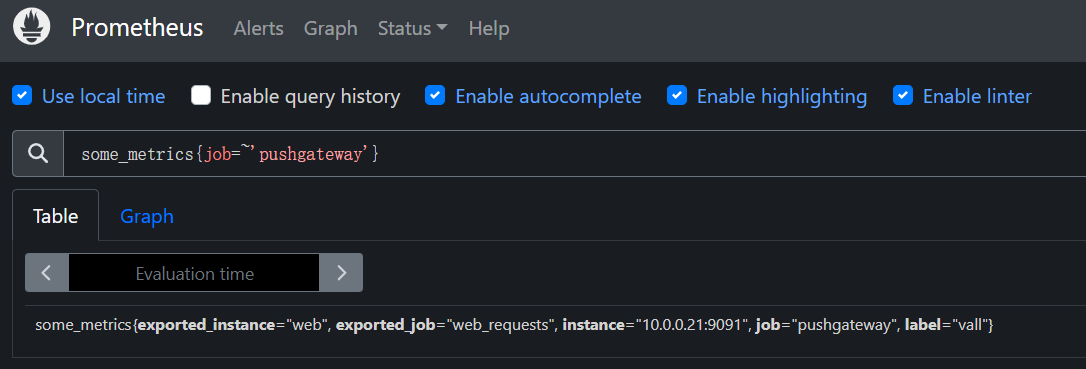
PromQL来查询我们的推送上去的语句 PromQL:some_metrics{job=~'pushgateway'}
客观来讲我们的生产中能不使用这个就尽量不要使用这个 pushgateway
# AlertManager
前面我们学习了Prometheus的时候了解到了Prometheus包含一个告警模块,也就是我们今天来学的AlertManager,Alertmanager主要用于接收Prometheus发送的告警信息,它支持丰富的告警通知渠道,而且很容易做到告警信息去重,降噪,分组等,是一款非常前卫的告警系统
通过在Prometheus中定义告警规则,Prometheus会周期性的对告警策略进行计算,如果满足告警触发条件就会想Alertmanager发送告警信息
# 1.概念
分组(Grouping)
Grouping 是 Alertmanager 把同类型的警报进行分组,合并多条警报到一个通知中。在生产环境中,特别是云环境下的业务之间密集耦合时,若出现多台 Instance 故障,可能会导致成千上百条警报触发。在这种情况下使用分组机制,可以把这些被触发的警报合并为一个警报进行通知,从而避免瞬间突发性的接受大量警报通知,使得管理员无法对问题进行快速定位
举个栗子,在Kubernetes集群中,运行着重量级规模的实例,即便是集群中持续很小一段时间的网络延迟或者延迟导致网络抖动,也会引发大量类似服务应用无法连接 DB 的故障。如果在警报规则中定义每一个应用实例都发送警报,那么到最后的结果就是 会有大量的警报信息发送给 Alertmanager
作为运维组或者相关业务组的开发人员,可能更关心的是在一个通知中就可以快速查看到哪些服务实例被本次故障影响了。为此,我们对服务所在集群或者服务警报名称的维度进行分组配置,把警报汇总成一条通知时,就不会受到警报信息的频繁发送影响了
抑制(Inhibition)
Inhibition 是 当某条警报已经发送,停止重复发送由此警报引发的其他异常或故障的警报机制
在生产环境中,IDC托管机柜中,若每一个机柜接入层仅仅是单台交换机,那么该机柜接入交换机故障会造成机柜中服务器非 up 状态警报。再有服务器上部署的应用服务不可访问也会触发警报
这时候,可以通过在 Alertmanager 配置忽略由于交换机故障而造成的此机柜中的所有服务器及其应用不可达而产生的警报
在我们的灾备体系中,当原有集群故障宕机业务彻底无法访问的时候,会把用户流量切换到备份集群中,这样为故障集群及其提供的各个微服务状态发送警报机会失去了意义,此时, Alertmanager 的抑制特性就可以在一定程度上避免管理员收到过多无用的警报通知
静默(Silences )
Silences 提供了一个简单的机制,根据标签快速对警报进行静默处理;对传进来的警报进行匹配检查,如果接受到警报符合静默的配置,Alertmanager 则不会发送警报通知
以上除了分组、抑制是在 Alertmanager 配置文件中配置,静默是需要在 WEB UI 界面中设置临时屏蔽指定的警报通知
路由(route)
用于配置 Alertmanager 如何处理传入的特定类型的告警通知,其基本逻辑是根据路由匹配规则的匹配结果来确定处理当前报警通知的路径和行为
# 2.配置详解
global:
# 经过此时间后,如果尚未更新告警,则将告警声明为已恢复。(即prometheus没有向alertmanager发送告警了)
resolve_timeout: 5m
# 配置发送邮件信息
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: '742899387@qq.com'
smtp_auth_username: '742899387@qq.com'
smtp_auth_password: 'password'
smtp_require_tls: false
# 读取告警通知模板的目录。
templates:
- '/etc/alertmanager/template/*.tmpl'
# 所有报警都会进入到这个根路由下,可以根据根路由下的子路由设置报警分发策略
route:
# 先解释一下分组,分组就是将多条告警信息聚合成一条发送,这样就不会收到连续的报警了。
# 将传入的告警按标签分组(标签在prometheus中的rules中定义),例如:
# 接收到的告警信息里面有许多具有cluster=A 和 alertname=LatencyHigh的标签,这些个告警将被分为一个组。
# 如果不想使用分组,可以这样写group_by: [...]
group_by: ['alertname', 'cluster', 'service']
# 第一组告警发送通知需要等待的时间,这种方式可以确保有足够的时间为同一分组获取多个告警,然后一起触发这个告警信息。
group_wait: 30s
# 发送第一个告警后,等待"group_interval"发送一组新告警。
group_interval: 5m
# 分组内发送相同告警的时间间隔。这里的配置是每3小时发送告警到分组中。举个例子:收到告警后,一个分组被创建,等待5分钟发送组内告警,如果后续组内的告警信息相同,这些告警会在3小时后发送,但是3小时内这些告警不会被发送。
repeat_interval: 3h
# 这里先说一下,告警发送是需要指定接收器的,接收器在receivers中配置,接收器可以是email、webhook、pagerduty、wechat等等。一个接收器可以有多种发送方式。
# 指定默认的接收器
receiver: team-X-mails
# 下面配置的是子路由,子路由的属性继承于根路由(即上面的配置),在子路由中可以覆盖根路由的配置
# 下面是子路由的配置
routes:
# 使用正则的方式匹配告警标签
- match_re:
# 这里可以匹配出标签含有service=foo1或service=foo2或service=baz的告警
service: ^(foo1|foo2|baz)$
# 指定接收器为team-X-mails
receiver: team-X-mails
# 这里配置的是子路由的子路由,当满足父路由的的匹配时,这条子路由会进一步匹配出severity=critical的告警,并使用team-X-pager接收器发送告警,没有匹配到的告警会由父路由进行处理。
routes:
- match:
severity: critical
receiver: team-X-pager
# 这里也是一条子路由,会匹配出标签含有service=files的告警,并使用team-Y-mails接收器发送告警
- match:
service: files
receiver: team-Y-mails
# 这里配置的是子路由的子路由,当满足父路由的的匹配时,这条子路由会进一步匹配出severity=critical的告警,并使用team-Y-pager接收器发送告警,没有匹配到的会由父路由进行处理。
routes:
- match:
severity: critical
receiver: team-Y-pager
# 该路由处理来自数据库服务的所有警报。如果没有团队来处理,则默认为数据库团队。
- match:
# 首先匹配标签service=database
service: database
# 指定接收器
receiver: team-DB-pager
# 根据受影响的数据库对告警进行分组
group_by: [alertname, cluster, database]
routes:
- match:
owner: team-X
receiver: team-X-pager
# 告警是否继续匹配后续的同级路由节点,默认false,下面如果也可以匹配成功,会向两种接收器都发送告警信息(猜测。。。)
continue: true
- match:
owner: team-Y
receiver: team-Y-pager
# 下面是关于inhibit(抑制)的配置,先说一下抑制是什么:抑制规则允许在另一个警报正在触发的情况下使一组告警静音。其实可以理解为告警依赖。比如一台数据库服务器掉电了,会导致db监控告警、网络告警等等,可以配置抑制规则如果服务器本身down了,那么其他的报警就不会被发送出来。
inhibit_rules:
#下面配置的含义:当有多条告警在告警组里时,并且他们的标签alertname,cluster,service都相等,如果severity: 'critical'的告警产生了,那么就会抑制severity: 'warning'的告警。
- source_match: # 源告警(我理解是根据这个报警来抑制target_match中匹配的告警)
severity: 'critical' # 标签匹配满足severity=critical的告警作为源告警
target_match: # 目标告警(被抑制的告警)
severity: 'warning' # 告警必须满足标签匹配severity=warning才会被抑制。
equal: ['alertname', 'cluster', 'service'] # 必须在源告警和目标告警中具有相等值的标签才能使抑制生效。(即源告警和目标告警中这三个标签的值相等'alertname', 'cluster', 'service')
# 下面配置的是接收器
receivers:
# 接收器的名称、通过邮件的方式发送、
- name: 'team-X-mails'
email_configs:
# 发送给哪些人
- to: 'team-X+alerts@example.org'
# 是否通知已解决的警报
send_resolved: true
# 接收器的名称、通过邮件和pagerduty的方式发送、发送给哪些人,指定pagerduty的service_key
- name: 'team-X-pager'
email_configs:
- to: 'team-X+alerts-critical@example.org'
pagerduty_configs:
- service_key: <team-X-key>
# 接收器的名称、通过邮件的方式发送、发送给哪些人
- name: 'team-Y-mails'
email_configs:
- to: 'team-Y+alerts@example.org'
# 接收器的名称、通过pagerduty的方式发送、指定pagerduty的service_key
- name: 'team-Y-pager'
pagerduty_configs:
- service_key: <team-Y-key>
# 一个接收器配置多种发送方式
- name: 'ops'
webhook_configs:
- url: 'http://prometheus-webhook-dingtalk.kube-ops.svc.cluster.local:8060/dingtalk/webhook1/send'
send_resolved: true
email_configs:
- to: '742899387@qq.com'
send_resolved: true
- to: 'soulchild@soulchild.cn'
send_resolved: true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
实际配置示例
## Alertmanager 配置文件
global:
resolve_timeout: 5m
# smtp配置
smtp_from: "123456789@qq.com"
smtp_smarthost: 'smtp.qq.com:465'
smtp_auth_username: "123456789@qq.com"
smtp_auth_password: "auth_pass"
smtp_require_tls: true
# email、企业微信的模板配置存放位置,钉钉的模板会单独讲如果配置。
templates:
- '/data/alertmanager/templates/*.tmpl'
# 路由分组
route:
receiver: ops
group_wait: 30s # 在组内等待所配置的时间,如果同组内,30秒内出现相同报警,在一个组内出现。
group_interval: 5m # 如果组内内容不变化,合并为一条警报信息,5m后发送。
repeat_interval: 24h # 发送报警间隔,如果指定时间内没有修复,则重新发送报警。
group_by: [alertname] # 报警分组
routes:
- match:
team: operations
group_by: [env,dc]
receiver: 'ops'
- match_re:
service: nginx|apache
receiver: 'web'
- match_re:
service: hbase|spark
receiver: 'hadoop'
- match_re:
service: mysql|mongodb
receiver: 'db'
# 接收器
# 抑制测试配置
- receiver: ops
group_wait: 10s
match:
status: 'High'
# ops
- receiver: ops # 路由和标签,根据match来指定发送目标,如果 rule的lable 包含 alertname, 使用 ops 来发送
group_wait: 10s
match:
team: operations
# web
- receiver: db # 路由和标签,根据match来指定发送目标,如果 rule的lable 包含 alertname, 使用 db 来发送
group_wait: 10s
match:
team: db
# 接收器指定发送人以及发送渠道
receivers:
# ops分组的定义
- name: ops
email_configs:
- to: '9935226@qq.com,10000@qq.com'
send_resolved: true
headers:
subject: "[operations] 报警邮件"
from: "警报中心"
to: "小煜狼皇"
# 钉钉配置
webhook_configs:
- url: http://localhost:8070/dingtalk/ops/send
# 企业微信配置
wechat_configs:
- corp_id: 'ww5421dksajhdasjkhj'
api_url: 'https://qyapi.weixin.qq.com/cgi-bin/'
send_resolved: true
to_party: '2'
agent_id: '1000002'
api_secret: 'Tm1kkEE3RGqVhv5hO-khdakjsdkjsahjkdksahjkdsahkj'
# web
- name: web
email_configs:
- to: '9935226@qq.com'
send_resolved: true
headers: { Subject: "[web] 报警邮件"} # 接收邮件的标题
webhook_configs:
- url: http://localhost:8070/dingtalk/web/send
- url: http://localhost:8070/dingtalk/ops/send
# db
- name: db
email_configs:
- to: '9935226@qq.com'
send_resolved: true
headers: { Subject: "[db] 报警邮件"} # 接收邮件的标题
webhook_configs:
- url: http://localhost:8070/dingtalk/db/send
- url: http://localhost:8070/dingtalk/ops/send
# hadoop
- name: hadoop
email_configs:
- to: '9935226@qq.com'
send_resolved: true
headers: { Subject: "[hadoop] 报警邮件"} # 接收邮件的标题
webhook_configs:
- url: http://localhost:8070/dingtalk/hadoop/send
- url: http://localhost:8070/dingtalk/ops/send
# 抑制器配置
inhibit_rules: # 抑制规则
- source_match: # 源标签警报触发时抑制含有目标标签的警报,在当前警报匹配 status: 'High'
status: 'High' # 此处的抑制匹配一定在最上面的route中配置不然,会提示找不key。
target_match:
status: 'Warning' # 目标标签值正则匹配,可以是正则表达式如: ".*MySQL.*"
equal: ['alertname','operations', 'instance'] # 确保这个配置下的标签内容相同才会抑制,也就是说警报中必须有这三个标签值才会被抑制。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
global
为全局设置,在 Alertmanager 配置文件中,只要全局设置配置了的选项,全部为公共设置,可以让其他设置继承,作为默认值,可以子参数中覆盖其设置。其中 resolve_timeout 用于设置处理超时时间,也是生命警报状态为解决的时间,这个时间会直接影响到警报恢复的通知时间,需要自行结合实际生产场景来设置主机的恢复时间,默认是5分钟。在全局设置中可以设置smtp服务,同时也支持slack、victorops、pagerduty等,在这里只讲我们常用的Email,钉钉,企业微信,同时也可以自己使用go语言开发的gubot进行二次开发,对接自定义webhook通知源
template
警报模板可以自定义通知的信息格式,以及其包含的对应警报指标数据,可以自定义Email、企业微信的模板,配置指定的存放位置,对于钉钉的模板会单独讲如何配置,这里的模板是指的发送的通知源信息格式模板,比如Email,企业微信
route
警报路由模块描述了在收到 Prometheus 生成的警报后,将警报信息发送给接收器 receiver 指定的目标地址规则。 Alertmanager 对传入的警报信息进行处理,根据所定义的规则与配置进行匹配。对于路由可以理解为树状结构,设置的第一个route是跟节点,往下的就是包含的子节点,每个警报传进来以后,会从配置的跟节点路由进入路由树,按照深度优先从左向右遍历匹配,当匹配的节点后停止,进行警报处理
| 参数 | 描述 |
|---|---|
| receiver: <string> | 发送警报的接收器名称 |
| group_by: ['label_name1,...'] | 根据 prometheus 的 lables 进行报警分组,这些警报会合并为一个通知发送给接收器,也就是警报分组 |
| match: [ <label_name>: <labelvalue>,...] | 通过此设置来判断当前警报中是否有标签的labelname,等同于labelvalue |
| match_re: [<label_name>: <regex>,...] | 通过正则表达式进行警报配置 |
| group_wait: [<duration>] | 设置从接受警报到发送的等待时间,若在等待时间中group接收到新的警报信息,这些警报会合并为一条发送,默认30s |
| group_interval: [<duration>] | 此设置控制的是 group 之间发送警报通知的间隔时间,默认5m |
| repeat_interval: [<duration>] | 此设置控制的是警报发送成功以后,没有对警报做解决操作的话,状态 Firing 没有变成 Inactive 或者 Pending ,会再次发送警报的的间隔时间,默认4h |
| routes: - <route>... |
路由匹配规则示例
route:
receiver: admin # 默认的接收器名称
group_wait: 30s # 在组内等待所配置的时间,如果同组内,30秒内出现相同报警,在一个组内出现。
group_interval: 5m # 如果组内内容不变化,5m后发送。
repeat_interval: 24h # 发送报警间隔,如果指定时间内没有修复,则重新发送报警
group_by: [alertname,cluster] # 报警分组,根据 prometheus 的 lables 进行报警分组,这些警报会合并为一个通知发送给接收器,也就是警报分组。
routes:
- match:
team: ops
group_by: [env,dc]
receiver: 'ops'
- match_re:
service: nginx|apache
receiver: 'web'
- match_re:
service: mysql|mongodb
receiver: 'db'
- match_re:
service: hbase|spark
receiver: 'hadoop'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
在以上的例子中,默认的警报组全部发送给 admin ,且根据路由按照 alertname cluster 进行警报分组。在子路由中的若匹配警报中的标签 team 的值为 ops,Alertmanager 会按照标签 env dc 进行警报分组然后发送给接收器 receiver ops配置的警报通知源,继续匹配的操作是对 service 标签进行匹配,并且配到了 nginx redis mongodb 的值,就会向接收器 receiver web配置的警报通知源发送警报信息
对这种匹配验证操作灰常考究个人的逻辑思维能力,这不是人干的事情呀~因此,Prometheus发布了一个 Routing tree editor (opens new window),用于检测Alertmanager的配置文件结构配置信息,然后调试。使用方法很简单,就是把 alertmanager.yml 的配置信心复制到这个站点,然后点击 Draw Routing Tree 按钮生成路由结构树,然后在 Match Label Set 前面输入以 {<label name> = "<value>"} 格式的警报标签,然后点击 Match Label Set 按钮会显示发送状态图
https://www.prometheus.io/webtools/alerting/routing-tree-editor/
然后我们可以使用 {service="nginx"} 和 {service="mysql"} 表达式来做匹配的规则用于验证其发送通知源是否为 receiver 中 web/db 的发送配置
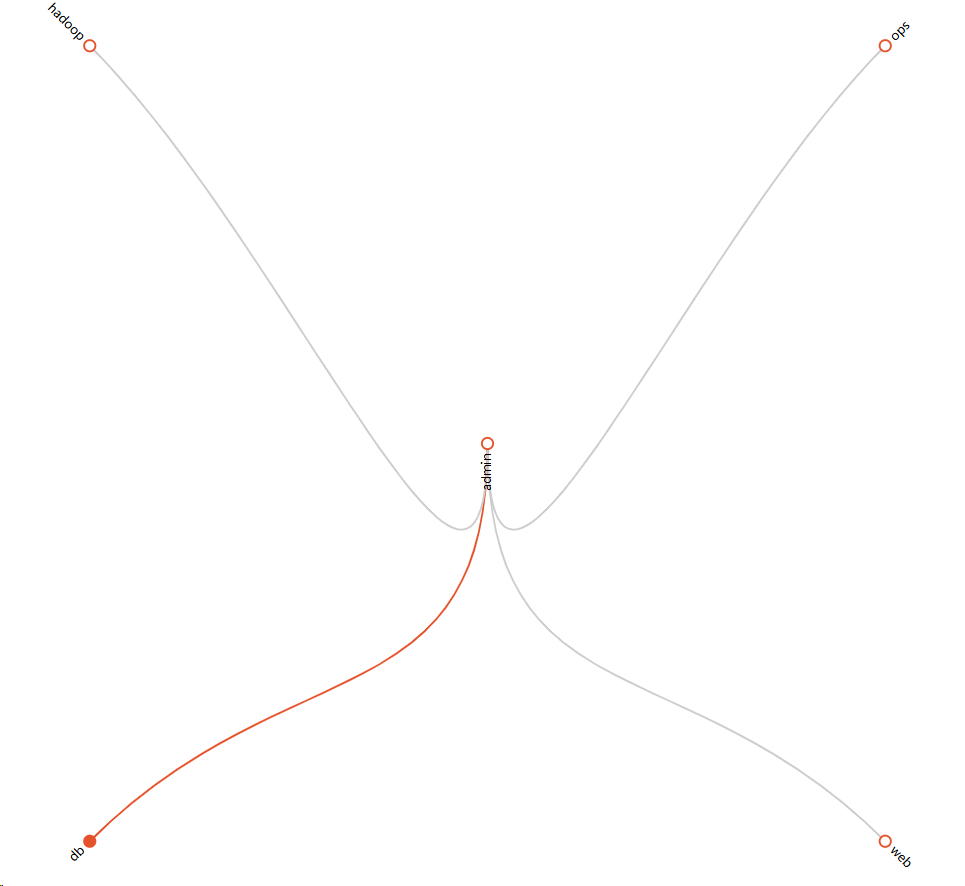 receiver 接收器
receiver 接收器
接受器是一个统称,每个 receiver 都有需要设置一个全局唯一的名称,并且对应一个或者多个通知方式,包括email、微信、Slack、钉钉等
官方现在满足的配置是:
name: <string>
email_config:
[ - <config> ]
hipchat_configs: #此模块配置已经被移除了
[ <config> ]
pagerduty_configs:
[ <config> ]
pushover_configs:
[ <config> ]
slack_configs:
[ <config> ]
opsgenie_configs:
[ <config> ]
webhook_configs:
[ <config> ]
victorops_configs:
[ <config> ]
webchat_configs:
[ <config> ]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
可以看到Alertmanager提供了很多种接收器的通知配置,我们可以使用webhook接收器来定义通知集成,支持用户自己定义编写
inhibit_rules 抑制器
inhibit_rules 模块中设置警报抑制功能,可以指定在特定条件下需要忽略的警报条件。可以使用此选项设置首选,比如优先处理某些警报,如果同一组中的警报同时发生,则忽略其他警报,合理使用 inhibit_rules ,可以减少频发发送没有意义的警报的产生
inhibit_rules 配置信息
trget_match:
[ <label_name>: <labelvalue>,... ]
trget_match_re:
[ <label_name>: <labelvalue>,... ]
source_match:
[ <label_name>: <labelvalue>,... ]
source_match_re:
[ <label_name>: <labelvalue>,... ]
[ equal: '[' <lable_name>, ...]']
2
3
4
5
6
7
8
9
# 3.警报接收通知器
# 3.1 Email
在 prometheus 中配置发现 alertmanager 规则
rule_files:
- "alert.rules.yml" # 自己创建下这个文件
alerting:
alertmanagers:
- static_configs:
- targets: ["10.0.0.21:9093"] # Alertmanager 的地址
2
3
4
5
6
7
在 alert.rules.yml 中添加告警规则
groups:
- name: memory_alert
rules:
- alert: HighMemoryUsage
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes) / node_memory_MemTotal_bytes * 100 > 80
for: 1m
labels:
severity: warning
annotations:
summary: "内存使用率高"
description: "内存使用率已达到 {{ $value }}%"
2
3
4
5
6
7
8
9
10
11
alertmanager 配置如下
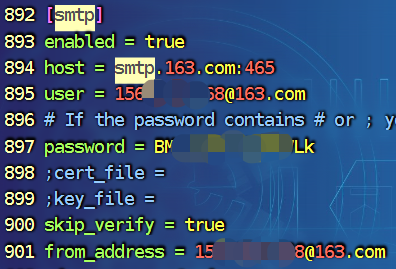
global:
resolve_timeout: 5m
# smtp配置
smtp_from: "156xxxx2568@163.com" # 发送邮件主题
smtp_smarthost: 'smtp.163.com:465' # 邮箱服务器的SMTP主机配置
smtp_auth_username: "156xxxx2568@163.com" # 登录用户名
smtp_auth_password: "BMxxxx6uhxxxxVLk" # 此处的auth password是邮箱的第三方登录授权密码,而非用户密码,尽量用QQ来测试。
smtp_require_tls: false # 有些邮箱需要开启此配置,这里使用的是163邮箱,仅做测试,不需要开启此功能。
route:
receiver: email-alert
group_wait: 30s # 在组内等待所配置的时间,如果同组内,30秒内出现相同报警,在一个组内出现。
group_interval: 5m # 如果组内内容不变化,合并为一条警报信息,5m后发送。
repeat_interval: 1h # 发送报警间隔,如果指定时间内没有修复,则重新发送报警。
group_by: [alertname] # 报警分组
routes:
- match:
severity: warning
receiver: 'email-alert'
- receiver: email-alert # 路由和标签,根据match来指定发送目标,如果 rule的lable 包含 alertname, 使用 ops 来发送
group_wait: 10s
match:
severity: warning
# 接收器指定发送人以及发送渠道
receivers:
# ops分组的定义
- name: email-alert
email_configs:
- to: '156xxxx2568@163.com' # 如果想发送多个人就以 ','做分割,写多个邮件人即可。
send_resolved: true
headers:
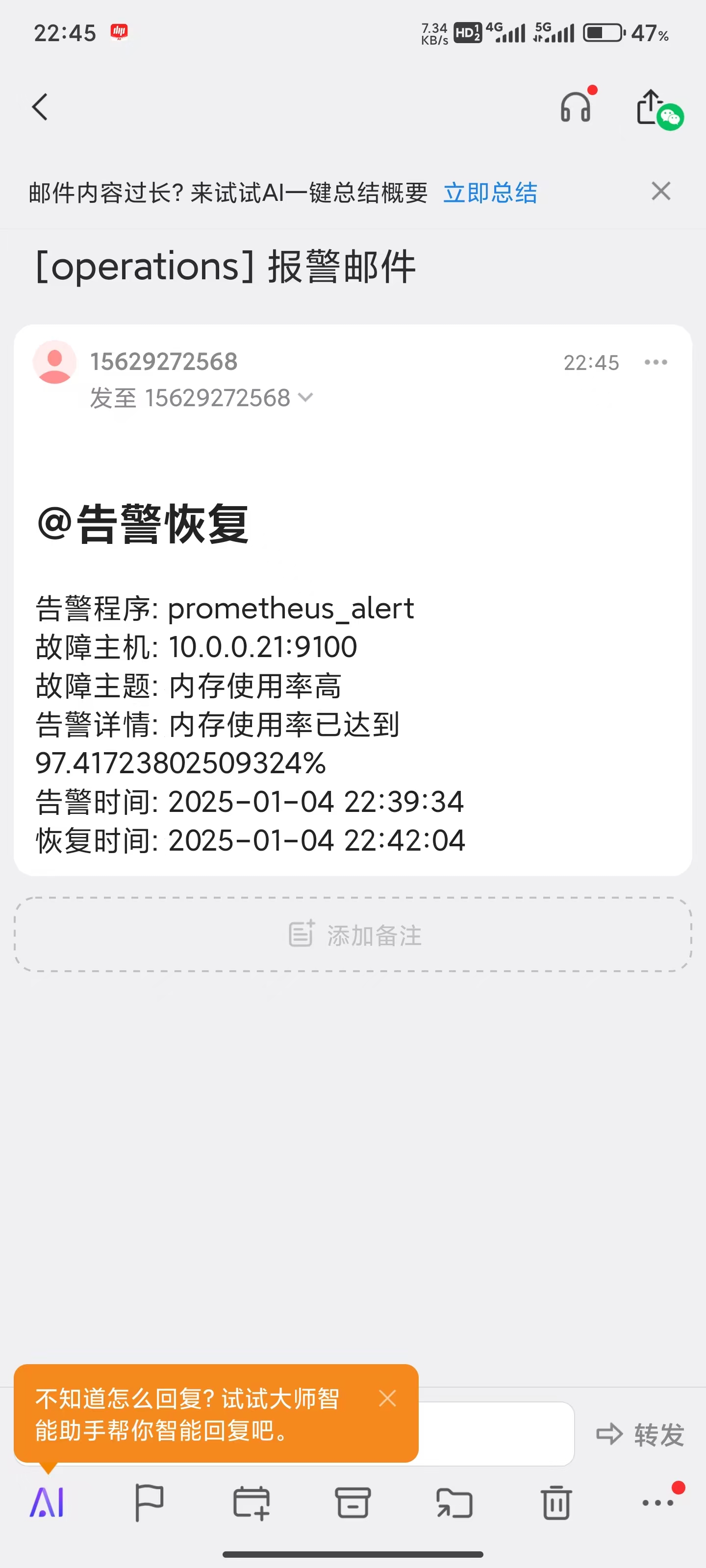
subject: "[operations] 报警邮件"
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
重启服务 prometheus 和 alertmanager
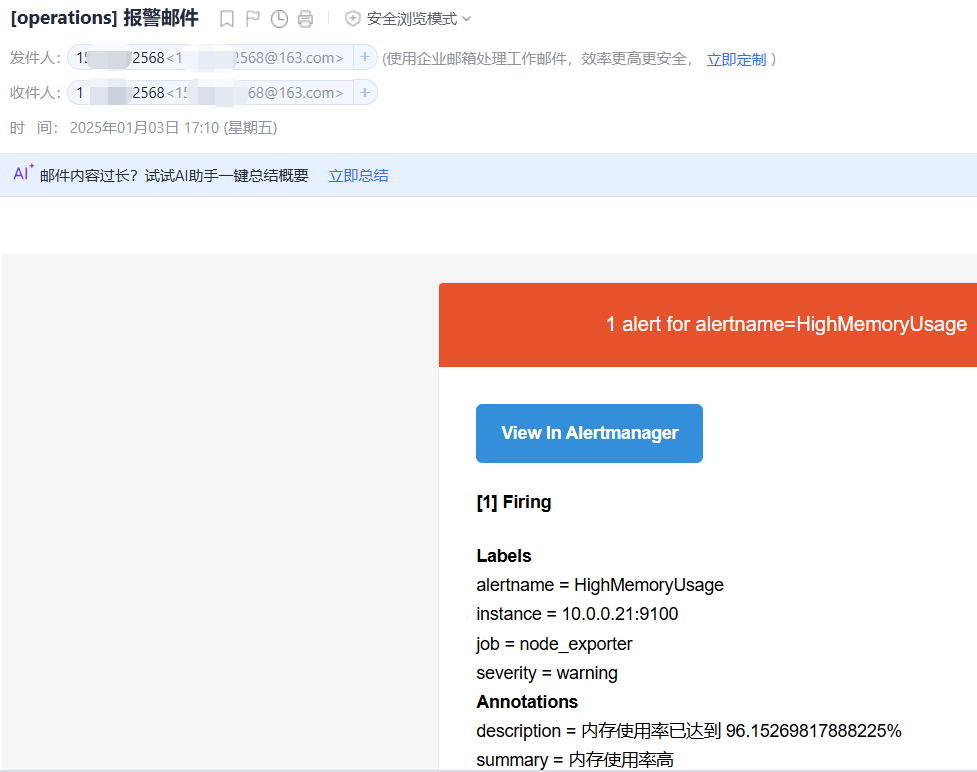
对内存进行压测:dd if=/dev/zero of=/dev/null bs=1G count=102400
报警短信如下
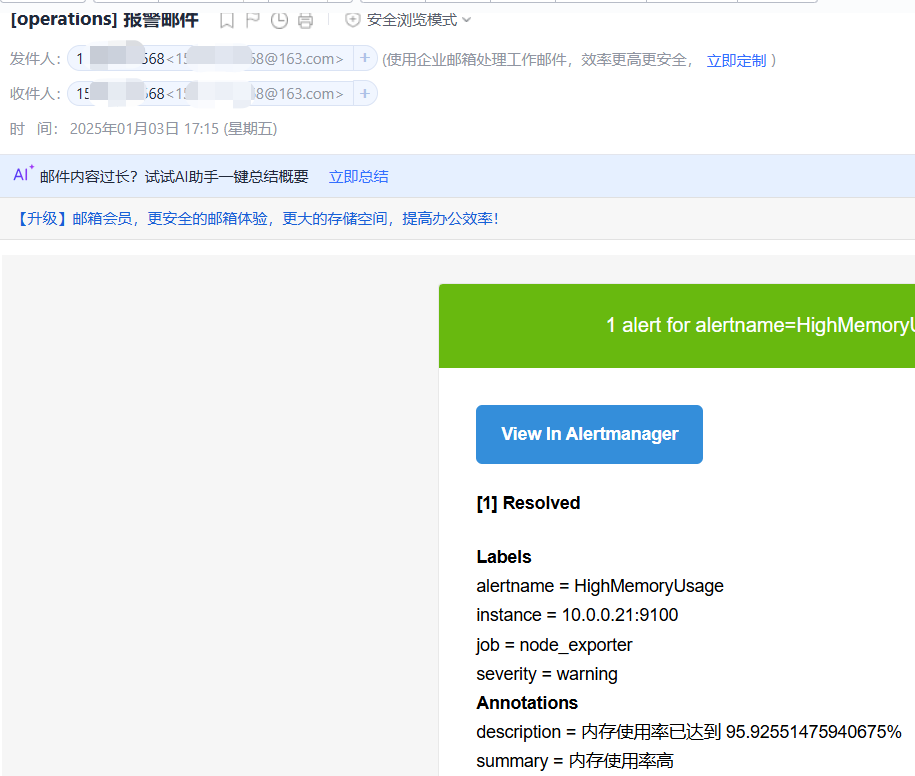
 恢复短信如下
恢复短信如下
 使用模板来自定义通知
使用模板来自定义通知
模板如下
{{ define "email.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
<h2>@告警通知</h2>
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }} <br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}
<h2>@告警恢复</h2>
告警程序: prometheus_alert <br>
故障主机: {{ .Labels.instance }} <br>
故障主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
告警时间: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }} <br>
恢复时间: {{ .EndsAt.Local.Format "2006-01-02 15:04:05" }}<br>
{{ end }}{{ end -}}
{{- end }}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
在 alertmanager 中导入此模板,在 receivers 中使用模板信息
templates: #定义微信告警内容模板
- '/opt/alertmanager/alertmanager/*.tmpl'
receivers:
# ops分组的定义
- name: email-alert
email_configs:
- to: '15xxxxx568@163.com' # 如果想发送多个人就以 ','做分割,写多个邮件人即可。
send_resolved: true
headers:
subject: "[operations] 报警邮件"
html: '{{ template "email.html" . }}'
2
3
4
5
6
7
8
9
10
11
重新加载配置文件信息:curl -X POST http://localhost:9093/-/reload
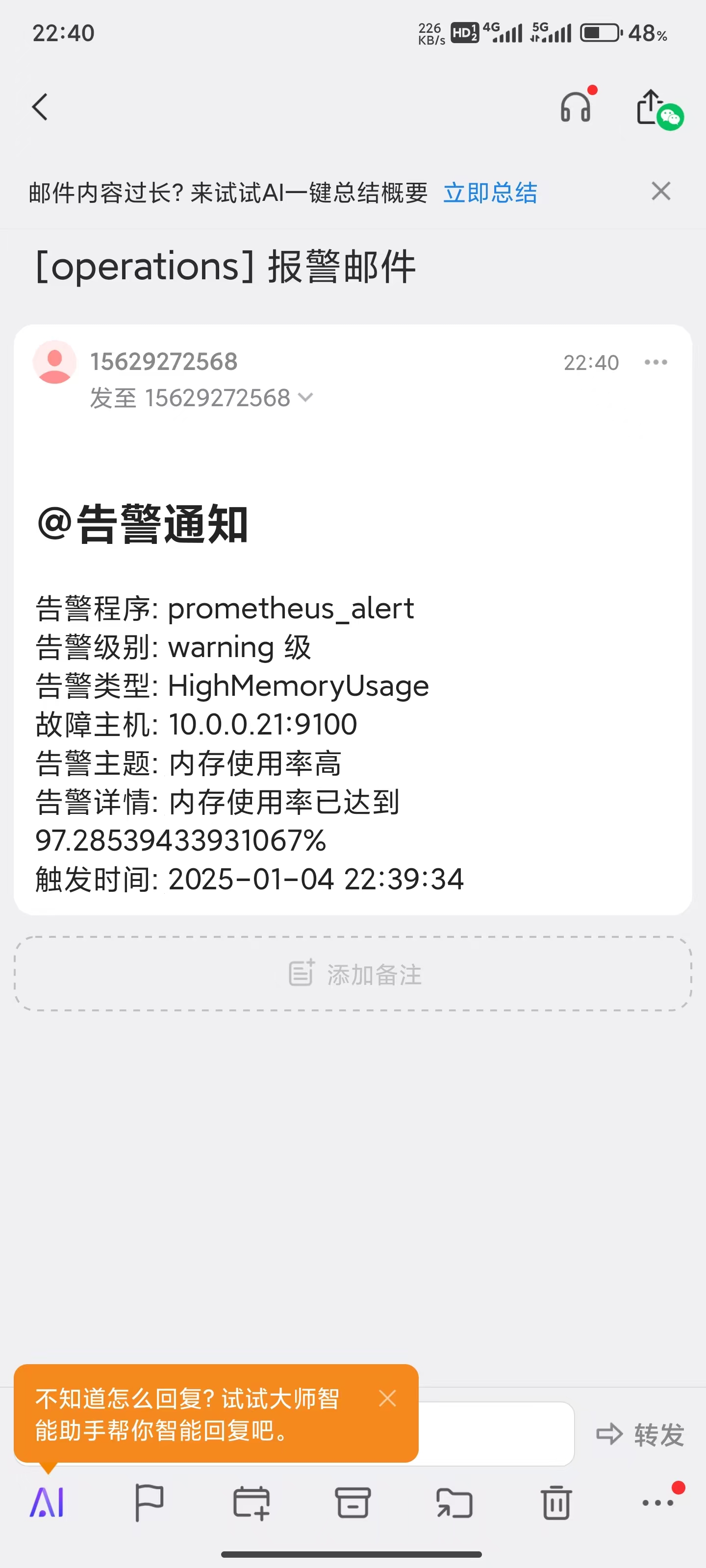
# 3.2 企业微信
prometheus -- alertmanager -- prometheus-webhook-wechat-main -- 企业微信
首先你要具有企业微信管理员的权限,如果没有可以自己注册一个,进行测试,我这里有自行注册的企业微信
具体创建过程省略
1.第一种方式是通过企业机器人实现报警,但是需要配置实际域名等,如果只是做测试,这种方式用不了。主要是需要获取到1.企业ID,2.告警部门ID,3.机器人ID,4.机器人密钥
2.第二种方式是通过企业微信群创建机器人,获取机器人的 webhook 进行配置
这里采用第二种方式进行演示
1.获取 weebhook
 2.启动 go 应用:prometheus-webhook-wechat-main
2.启动 go 应用:prometheus-webhook-wechat-main
企业微信 webhook 需要用到这个工具
下载地址:https://github.com/SecurityNeo/prometheus-webhook-wechat
文件种提供了 Dockerfile,也可以用 docker 部署,这里选择直接启用这个应用
vim config.yml
maxContentLength: 4096
targets:
webhook1:
url: xxx # 填上前面的 Webhook 地址
2
3
4
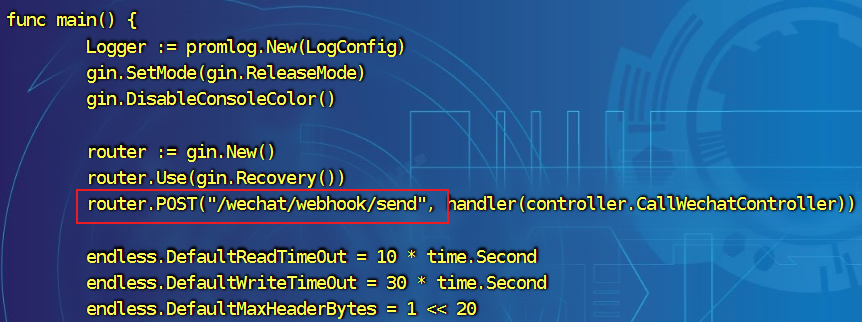
我们再到 ./cmd/main.go 中查看下项目访问路径,这里可以看到是:/wechat/webhook/send,等一下会用到
 启动应用:nohup ./prometheus-webhook-wechat --listen-port=':9999' &,这里设置了访问端口为 9999,默认为 80
启动应用:nohup ./prometheus-webhook-wechat --listen-port=':9999' &,这里设置了访问端口为 9999,默认为 80
3.配置 alertmanager.yml
主要是配置路由和接收器,以下是我做测试的例子
global:
resolve_timeout: 5m
# smtp配置
smtp_from: "156xxxx2568@163.com" # 发送邮件主题
smtp_smarthost: 'smtp.163.com:465' # 邮箱服务器的SMTP主机配置
smtp_auth_username: "156xxxx2568@163.com" # 登录用户名
smtp_auth_password: "BMqQpxxxxxxiUqVLk" # 此处的auth password是邮箱的第三方登录授权密码,而非用户密码,尽量用QQ来测试。
smtp_require_tls: false # 有些邮箱需要开启此配置,这里使用的是163邮箱,仅做测试,不需要开启此功能。
templates: #定义微信告警内容模板
- '/opt/alertmanager/alertmanager/wechat.tmpl'
route:
receiver: email-alert
group_wait: 30s # 在组内等待所配置的时间,如果同组内,30秒内出现相同报警,在一个组内出现。
group_interval: 5m # 如果组内内容不变化,合并为一条警报信息,5m后发送。
repeat_interval: 1h # 发送报警间隔,如果指定时间内没有修复,则重新发送报警。
group_by: [alertname] # 报警分组
routes:
- match:
severity: warning
receiver: 'wechat-webhook'
# 接收器指定发送人以及发送渠道
receivers:
# ops分组的定义
- name: email-alert
email_configs:
- to: '156xxxx2568@163.com' # 如果想发送多个人就以 ','做分割,写多个邮件人即可。
send_resolved: true
headers:
subject: "[operations] 报警邮件"
- name: 'wechat'
wechat_configs:
- corp_id: 'ww982xxxxxx442eea'
to_party: '1'
agent_id: '100xxx4'
api_secret: '18gWU4T9PKv-KAhIxxxxxKCbXopyDAWE'
send_resolved: true
message: '{{ template "wechat.default.message" . }}'
- name: 'wechat-webhook'
webhook_configs:
- url: "http://10.0.0.20:9999/wechat/webhook/send"
send_resolved: true # 是否发送恢复通知
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
其中最重要是就是在配置 receivers 时用到刚刚的路径:http://10.0.0.20:9999/wechat/webhook/send
4.配置通知模板
{{ define "__subject" }}
[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}]
{{ end }}
{{ define "__alert_list" }}{{ range . }}
---
>**告警主题**: {{ .Annotations.summary }}
>**告警类型**: {{ .Labels.alertname }}
>**告警级别**: {{ .Labels.severity }}
>**告警实例**: {{ .Labels.instance }}
>**告警内容**: {{ index .Annotations "description" }}
>**告警来源**: [{{ .GeneratorURL }}]({{ .GeneratorURL }})
>**告警时间**: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }}
{{ end }}{{ end }}
{{ define "__resolved_list" }}{{ range . }}
---
>**告警主题**: {{ .Annotations.summary }}
>**告警类型**: {{ .Labels.alertname }}
>**告警级别**: {{ .Labels.severity }}
>**告警实例**: {{ .Labels.instance }}
>**告警内容**: {{ index .Annotations "description" }}
>**告警来源**: [{{ .GeneratorURL }}]({{ .GeneratorURL }})
>**告警时间**: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }}
>**恢复时间**: {{ .EndsAt.Local.Format "2006-01-02 15:04:05" }}
{{ end }}{{ end }}
{{ define "msg.title" }}
{{ template "__subject" . }}
{{ end }}
{{ define "msg.content" }}
{{ if gt (len .Alerts.Firing) 0 }}
**产生<font color="warning">{{ .Alerts.Firing | len }}</font>个故障**
{{ template "__alert_list" .Alerts.Firing }}
{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}
**恢复<font color="info">{{ .Alerts.Resolved | len }}</font>个故障**
{{ template "__resolved_list" .Alerts.Resolved }}
{{ end }}
{{ end }}
{{ template "msg.title" . }}
{{ template "msg.content" . }}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
重新启用下,让 webhook 项目应用到自定义模板:
nohup ./prometheus-webhook-wechat --listen-port=':9999' --template.file=template.tmpl &
5.测试报警与恢复
dd if=/dev/zero of=/dev/null bs=1G count=102400
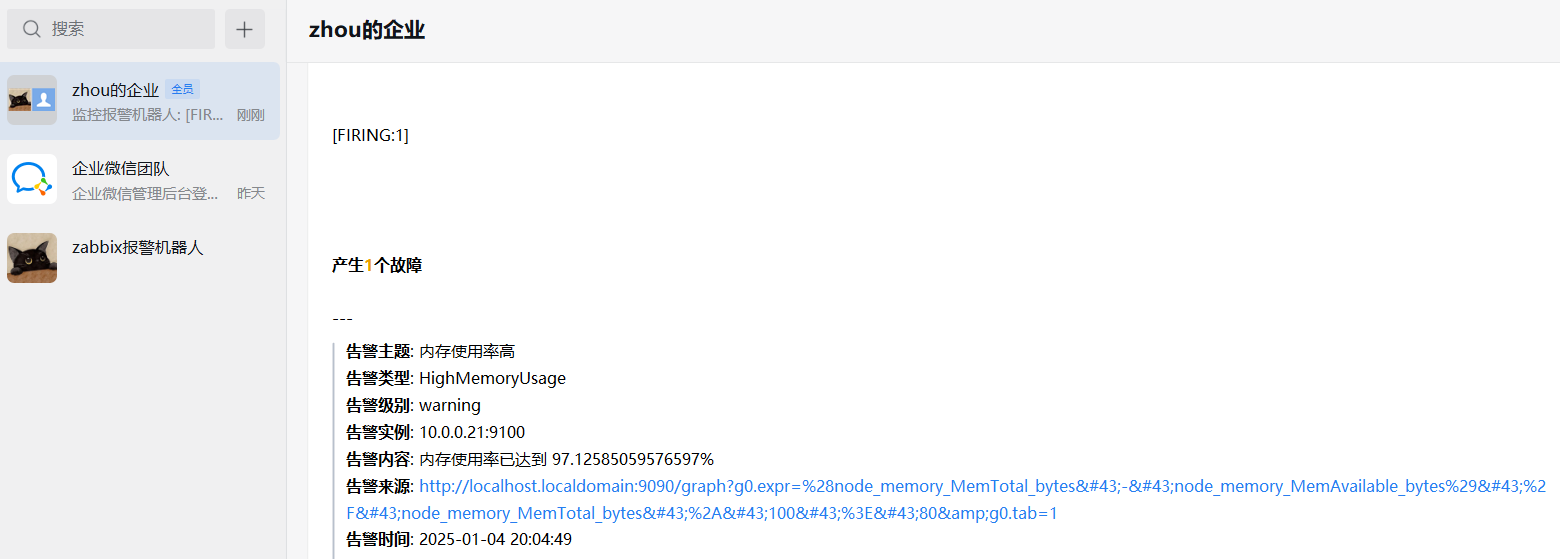
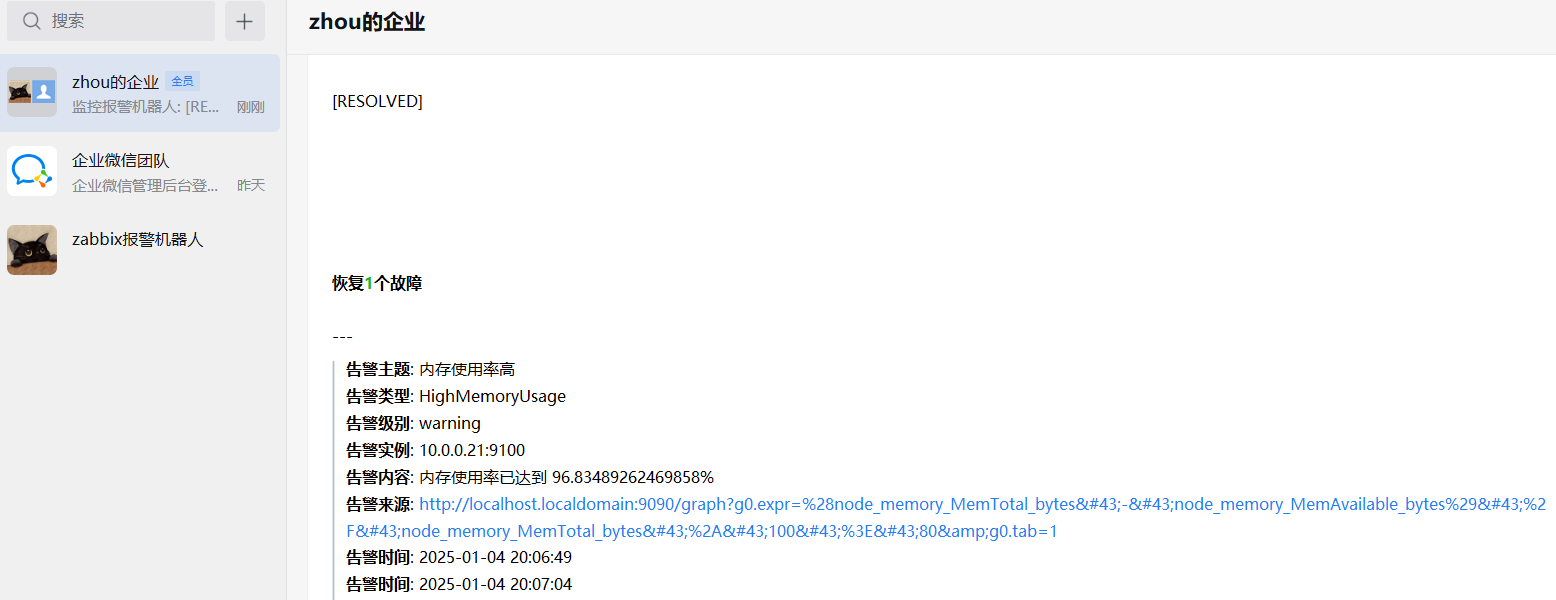
发现了1个问题,提供的告警来源主机是 localhost,接下来将 localhost 修改为 prometheus 主机的IP
重新启动 promethus(加上参数):nohup ./prometheus --web.external-url=http://10.0.0.20:9090 &
如果不方便重启 prometheus 还有一些别的方法,可以自行查阅资料
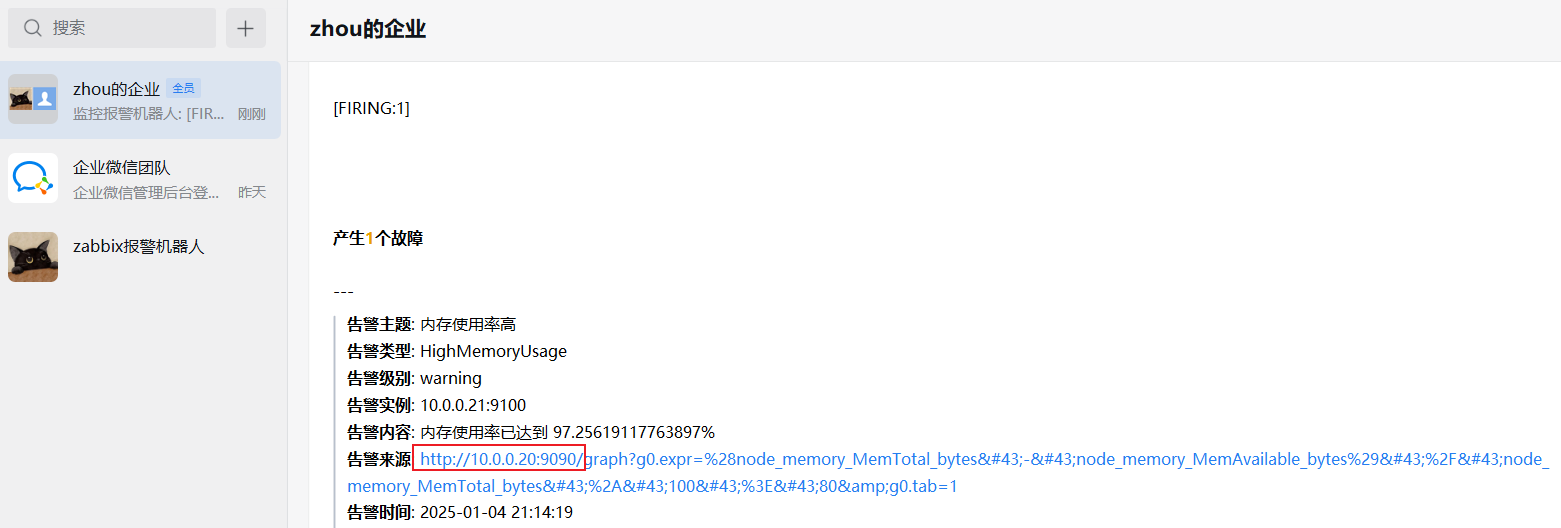
# 3.3 钉钉机器人 WebHook
prometheus -- alertmanager -- rometheus-webhook-dingtalk -- 钉钉
注册钉钉:http://oa.dingtalk.com
随便注册1个企业
 添加钉钉机器人(用 PC 端钉钉添加)
添加钉钉机器人(用 PC 端钉钉添加)
 我们一般把告警信息发送给一个部门,然后把处理故障的人员添加到这个部门
我们一般把告警信息发送给一个部门,然后把处理故障的人员添加到这个部门
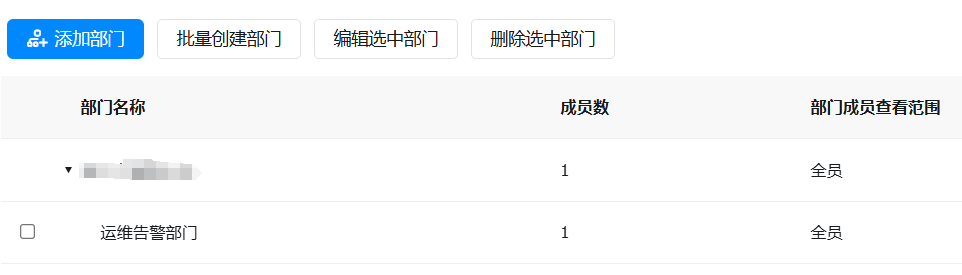
创建1个子部门,然后把自己的账号添加到该部门下
 回到钉钉,发现自动创建了部门群
回到钉钉,发现自动创建了部门群
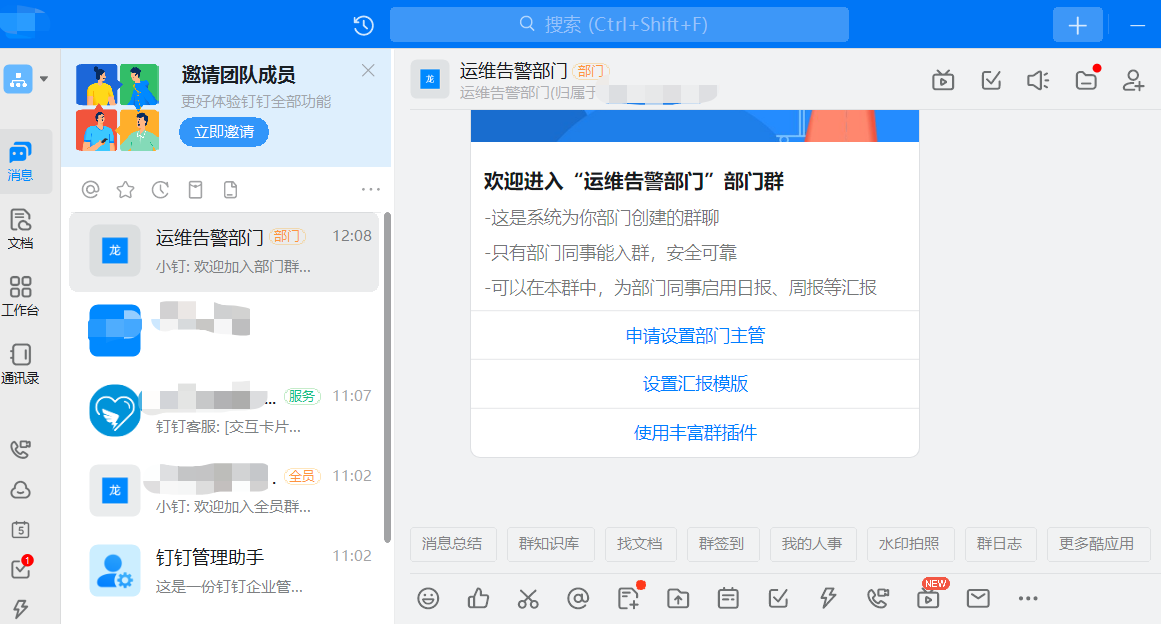 设置 -- 机器人 -- 添加机器人 -- 自定义 -- 添加
设置 -- 机器人 -- 添加机器人 -- 自定义 -- 添加
 添加机器人时需要添加 IP 地址/段,如果是虚拟环境部署的应用,可以在 ip138.com 查询本机IP
添加机器人时需要添加 IP 地址/段,如果是虚拟环境部署的应用,可以在 ip138.com 查询本机IP
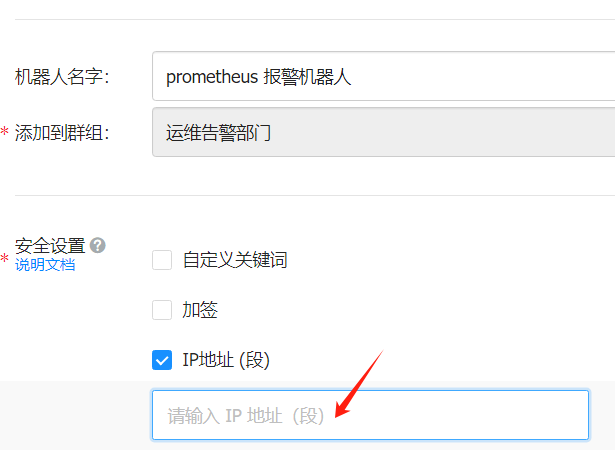 保存 webhook 地址
保存 webhook 地址
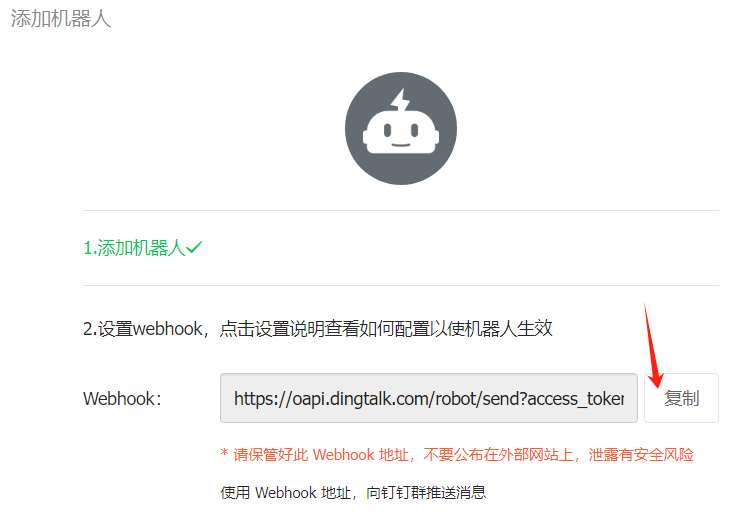 下载 prometheus-webhook-dingtalk:https://github.com/timonwong/prometheus-webhook-dingtalk
下载 prometheus-webhook-dingtalk:https://github.com/timonwong/prometheus-webhook-dingtalk
此项目使用 go 环境,先给下载 go ,然后配置环境变量
编译项目:go build -o prometheus-webhook-dingtalk ./cmd/prometheus-webhook-dingtalk
配置文件(config.yml):cp config.example.yml config.yml
targets:
webhook1:
url: https://oapi.dingtalk.com/robot/send?access_token=7e9xxxxbb6xxxxa7b0c8b2e725aadxxxx24a2f9fae0d6
secret: SEC000000000000000000000
2
3
4
查看路由发现访问路径为(main.go):/dingtalk/webhook1/send
启动项目:nohup ./prometheus-webhook-dingtalk --web.listen-address=:8888 &
配置 alertmanager.yml
- name: 'dingtalk-webhook'
webhook_configs:
- url: "http://10.0.0.20:8888/dingtalk/webhook1/send"
send_resolved: true
2
3
4
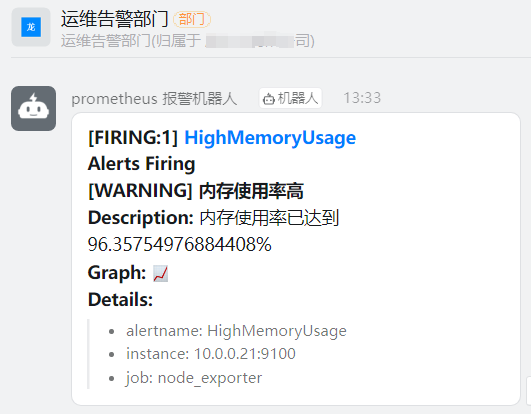
测试报警与恢复
# 
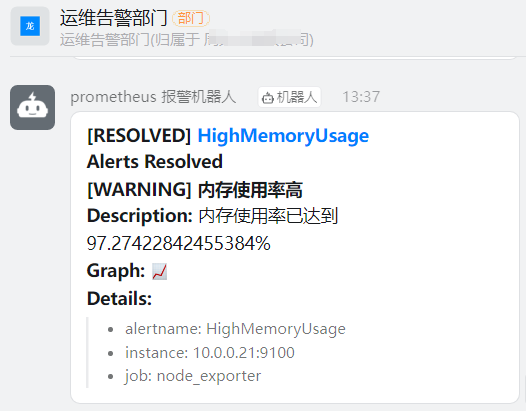 3.4 问题记录
3.4 问题记录
1.配置 go 环境变量
vim /etc/profile
export PATH=$PATH:/usr/local/go/bin
source /etc/profile
go version
2
3
4
2.编译 go 项目时卡住了
# 配置代理命令
go env -w GOPROXY=https://goproxy.cn,direct
# 验证代理是否生效 输出类似 GOPROXY="https://goproxy.cn,direct"
go env | grep GOPROXY
# 清理并重新拉取依赖
go mod tidy
go build -o prometheus-webhook-wechat ./cmd/main.go
2
3
4
5
6
7
3.通过 main.go 找到 webhook 正确处理请求的地址
4.修改 localhost 显示为我的 prometheus 的主机IP
重新启动 promethus(加上参数):nohup ./prometheus --web.external-url=http://10.0.0.20:9090 &
还可以修改模板信息来改变
5.这些应用也提供了 Dockerfile 的方式帮助从 docker 构建,也可以试一下
# 3.5 警报通知模板
Prometheus 创建警报转发给 Alertmanager,Alertmanager 会根据不同的 Label 向不同的 Receiver 发送警报通知,如 Email、钉钉、企业微信、飞书、短信等等,所有 Receiver都一个接收模板,然后通过模板格式化以后发送警报信息给 Receiver
Alertmanager 自带的模板是基于 Go 语言的 template 模板,用户可以根据自己的需求去定义自己需要的模板
邮件模板
{{ define "email.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}{{ range .Alerts }}
<h2>@告警通知</h2>
告警程序: prometheus_alert <br>
告警级别: {{ . Labels.severity }} 级 <br>
告警类型: {{ . Labels.alertname }} <br>
故障主机: {{ . Labels.instance }} <br>
告警主题: {{ . Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ . StartsAt.Local.Format "2006-01-02 15:04:05" }} <br>
{{ end }}{{ end -}}
{{- if gt (len .Alerts.Resolved) 0 -}}{{ range .Alerts }}
<h2>@告警恢复</h2>
告警程序: prometheus_alert <br>
故障主机: {{ .Labels.instance }} <br>
故障主题: {{ .Annotations.summary }} <br>
告警详情:{{ .Annotations.description }} <br>
告警时间: {{ .StartsAt.Local.Format "2006-01-02 15:04:05" }} <br>
恢复时间: {{ .EndsAt.Local.Format "2006-01-02 15:04:05" }}<br>
{{ end }}{{ end -}}
{{- end }}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
Wechat 模板
cat wechat.tmpl
## wechat模板
{{ define "wechat.default.message" }}
{{ if gt (len .Alerts.Firing) 0 -}}
Alerts Firing:
{{ range .Alerts }}
警报级别:{{ .Labels.status }}
警报类型:{{ .Labels.alertname }}
故障主机: {{ .Labels.instance }}
警报主题: {{ .Annotations.summary }}
警报详情: {{ .Annotations.description }}
⏱ : {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- end }}
{{- end }}
{{ if gt (len .Alerts.Resolved) 0 -}}
Alerts Resolved:
{{ range .Alerts }}
警报级别:{{ .Labels.status }}
警报类型:{{ .Labels.alertname }}
故障主机: {{ .Labels.instance }}
警报主题: {{ .Annotations.summary }}
警报详情: {{ .Annotations.description }}
⏱ : {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
⏲ : {{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{{- end }}
{{- end }}
{{- end }}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
钉钉模板
cd /etc/prometheus-webhook-dingtalk/template
cat default.tmpl
{{ define "__subject" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ .GroupLabels.SortedPairs.Values | join " " }} {{ if gt (len .CommonLabels) (len .GroupLabels) }}({{ with .CommonLabels.Remove .GroupLabels.Names }}{{ .Values | join " " }}{{ end }}){{ end }}{{ end }}
{{ define "__alertmanagerURL" }}{{ .ExternalURL }}/#/alerts?receiver={{ .Receiver }}{{ end }}
{{ define "__text_alert_list" }}{{ range . }}
**Labels**
{{ range .Labels.SortedPairs }}> - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}
**Annotations**
{{ range .Annotations.SortedPairs }}> - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}
**Source:** [{{ .GeneratorURL }}]({{ .GeneratorURL }})
{{ end }}{{ end }}
{{/* Firing */}}
{{ define "default.__text_alert_list" }}{{ range . }}
**Trigger Time:** {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }}
**Summary:** {{ .Annotations.summary }}
**Description:** {{ .Annotations.description }}
**Graph:** [📈 ]({{ .GeneratorURL }})
**Details:**
{{ range .Labels.SortedPairs }}{{ if and (ne (.Name) "severity") (ne (.Name) "summary") }}> - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}{{ end }}
{{ end }}{{ end }}
{{/* Resolved */}}
{{ define "default.__text_resolved_list" }}{{ range . }}
**Trigger Time:** {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }}
**Resolved Time:** {{ dateInZone "2006.01.02 15:04:05" (.EndsAt) "Asia/Shanghai" }}
**Summary:** {{ .Annotations.summary }}
**Graph:** [📈 ]({{ .GeneratorURL }})
**Details:**
{{ range .Labels.SortedPairs }}{{ if and (ne (.Name) "severity") (ne (.Name) "summary") }}> - {{ .Name }}: {{ .Value | markdown | html }}
{{ end }}{{ end }}
{{ end }}{{ end }}
{{/* Default */}}
{{ define "default.title" }}{{ template "__subject" . }}{{ end }}
{{ define "default.content" }}#### \[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}\] **[{{ index .GroupLabels "alertname" }}]({{ template "__alertmanagerURL" . }})**
{{ if gt (len .Alerts.Firing) 0 -}}

**Alerts Firing**
{{ template "default.__text_alert_list" .Alerts.Firing }}
{{- end }}
{{ if gt (len .Alerts.Resolved) 0 -}}

**Alerts Resolved**
{{ template "default.__text_resolved_list" .Alerts.Resolved }}
{{- end }}
{{- end }}
{{/* Legacy */}}
{{ define "legacy.title" }}{{ template "__subject" . }}{{ end }}
{{ define "legacy.content" }}#### \[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}\] **[{{ index .GroupLabels "alertname" }}]({{ template "__alertmanagerURL" . }})**
{{ template "__text_alert_list" .Alerts.Firing }}
{{- end }}
{{/* Following names for compatibility */}}
{{ define "ding.link.title" }}{{ template "default.title" . }}{{ end }}
{{ define "ding.link.content" }}{{ template "default.content" . }}{{ end }}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
# Grafana + OneAlert 告警
官网:https://www.aiops.com/
1.进入 OneAlert 的智能告警平台 CloudAlert
2.配置通知策略

3.配置分派策略
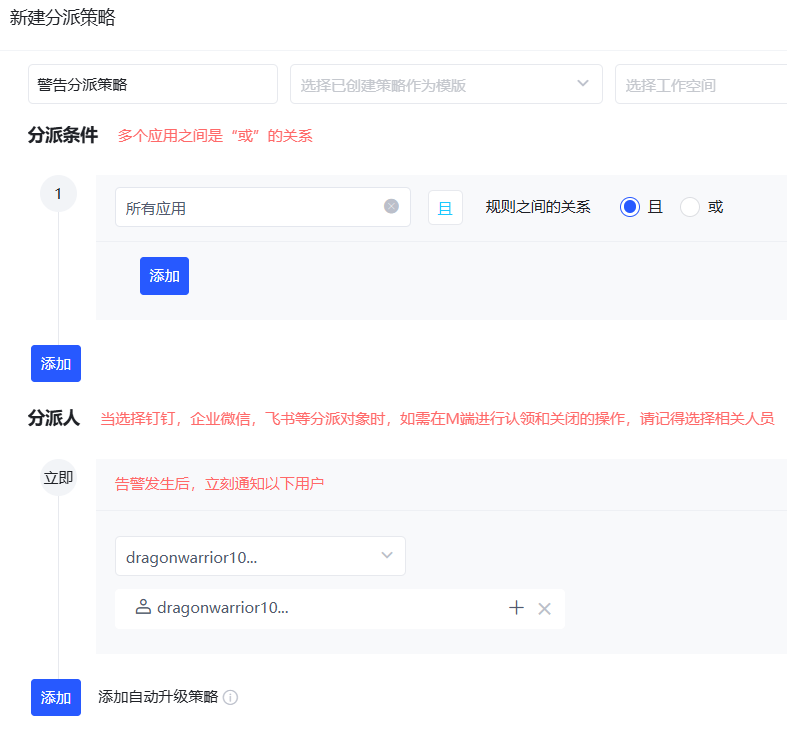
4.集成监控工具
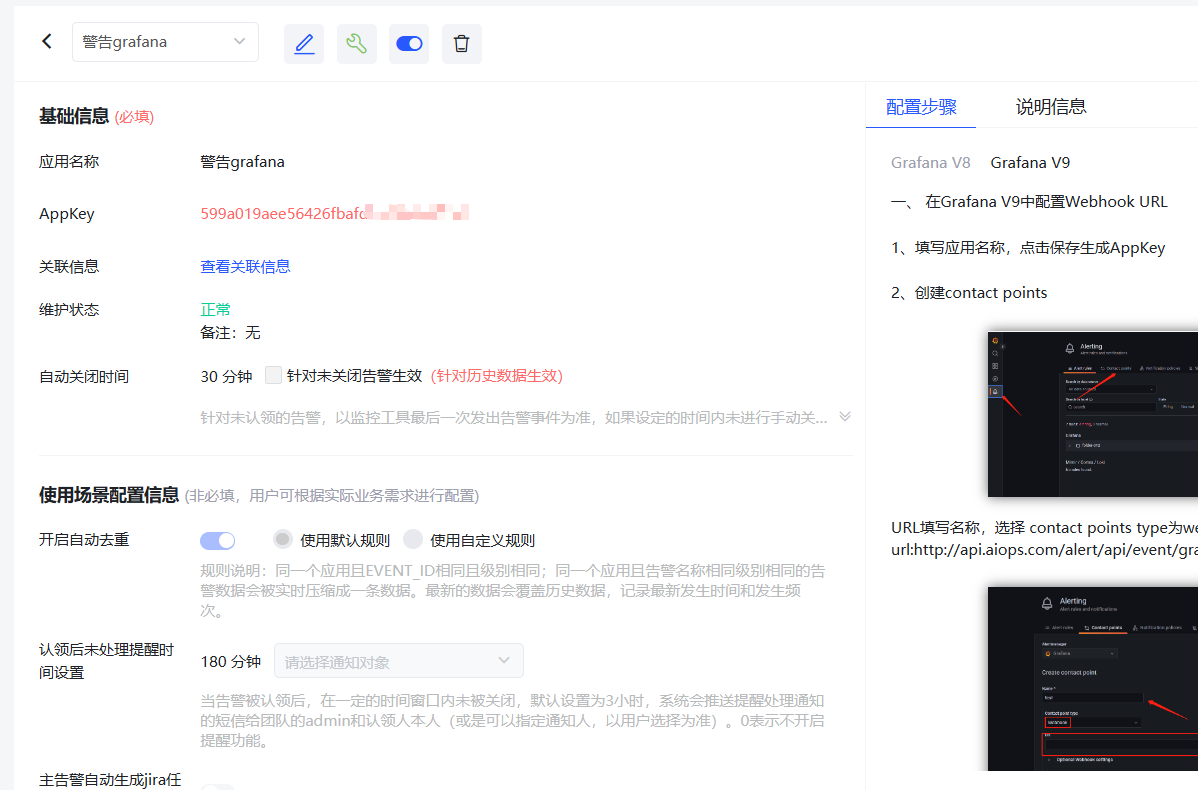
5.Grafana 绑定 OneAlert
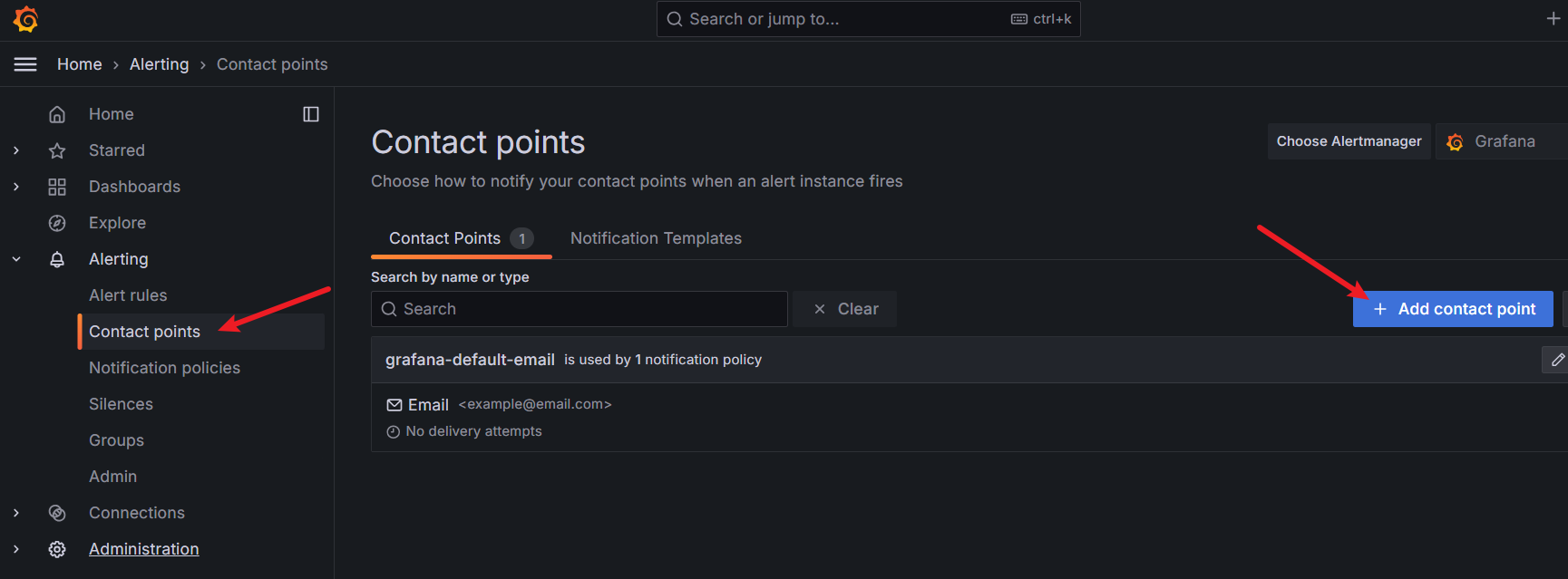
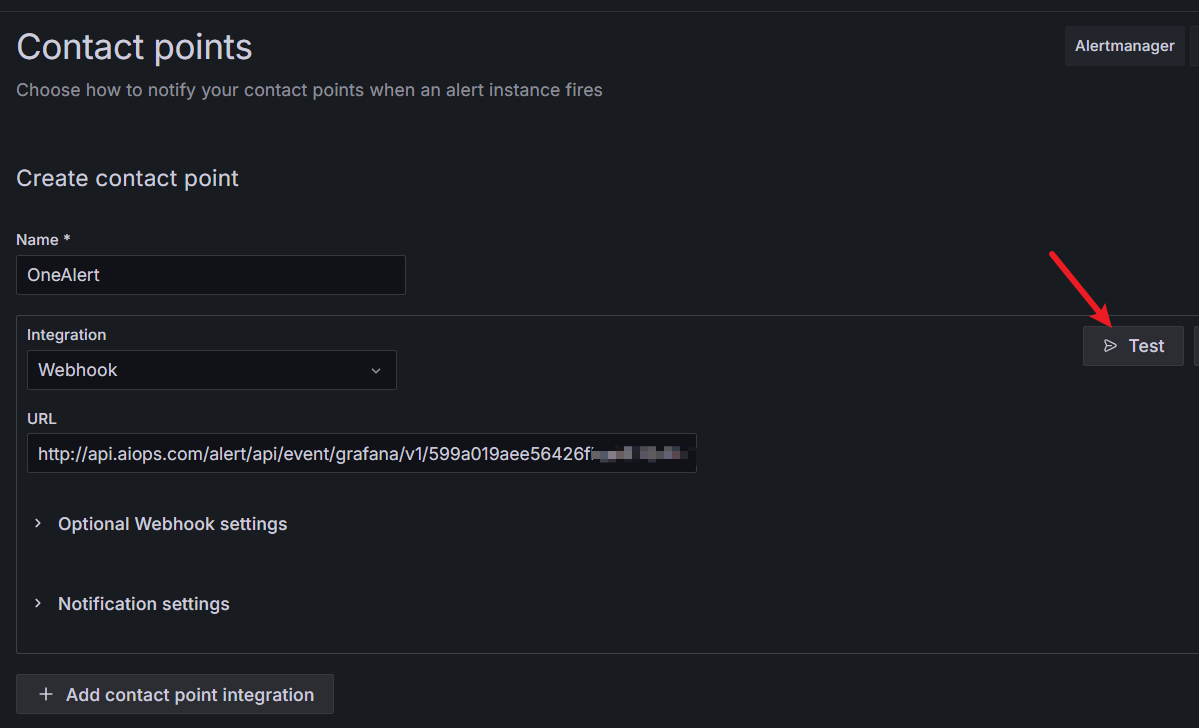
配置好后,可以点 Test 试一下,发现有个告警电话打过来了
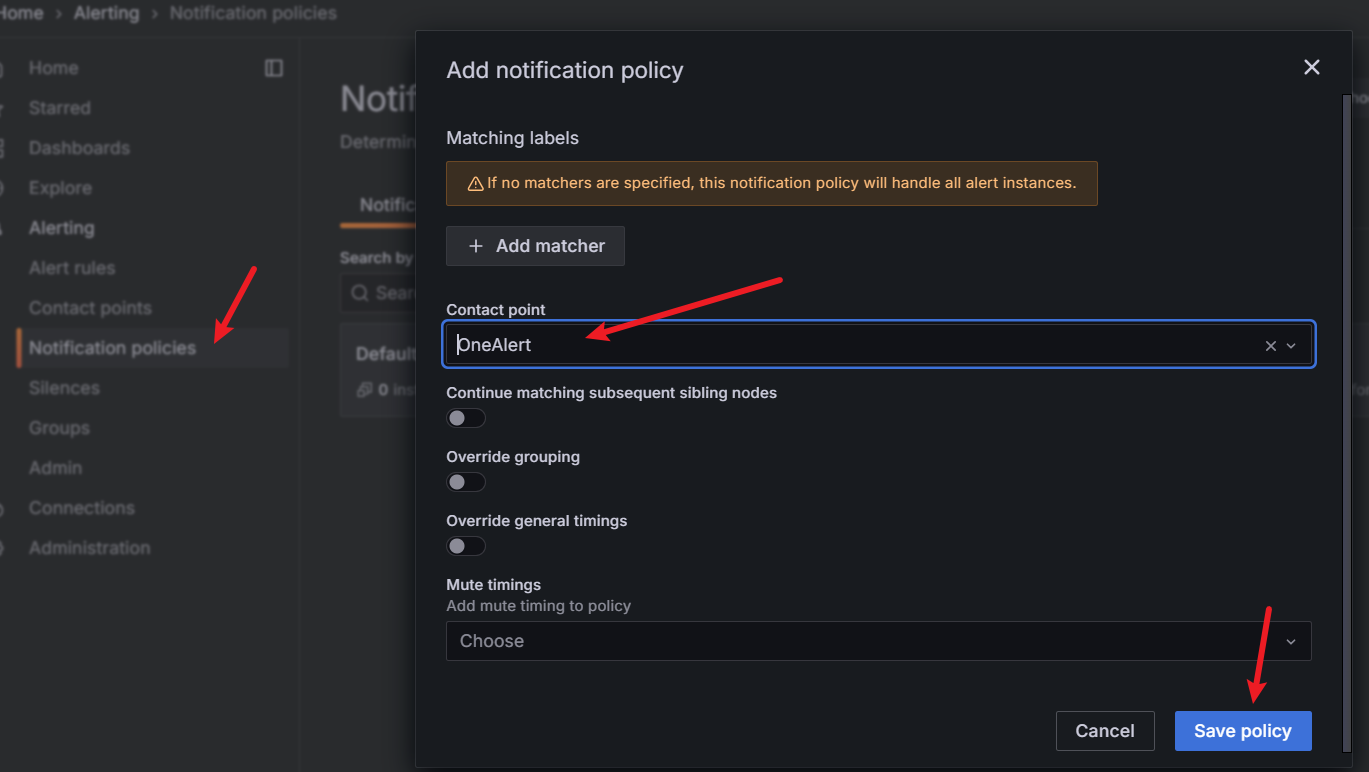
6.设置告警策略
7.设置告警
拿之前创建的模板举例
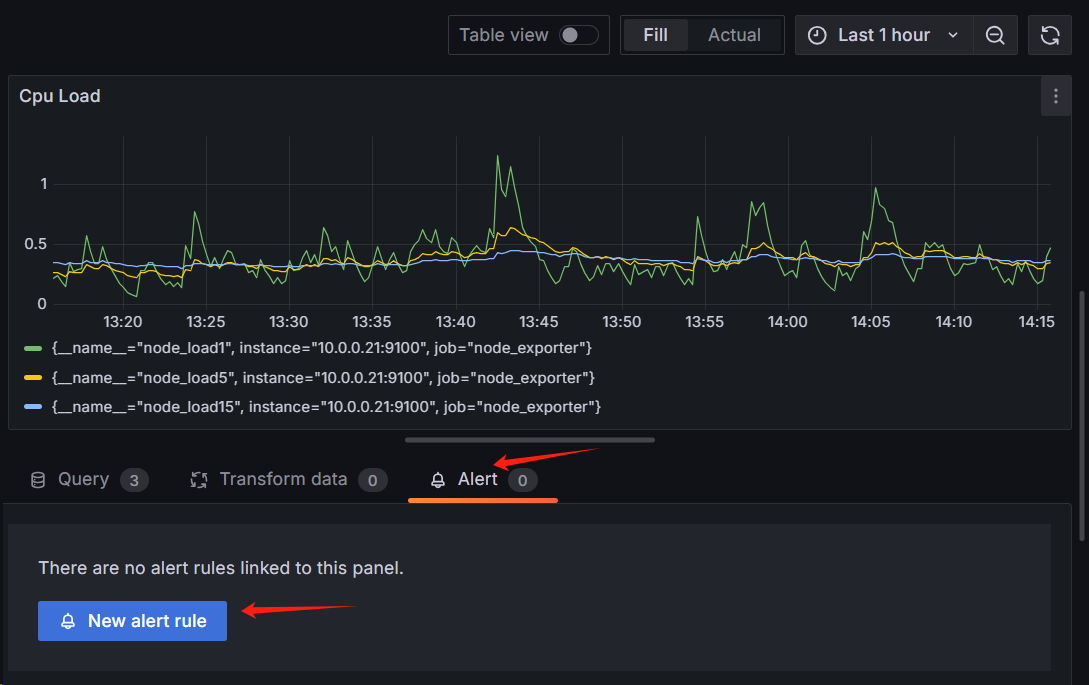
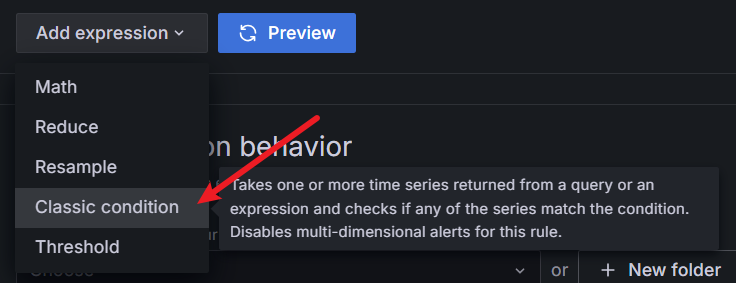
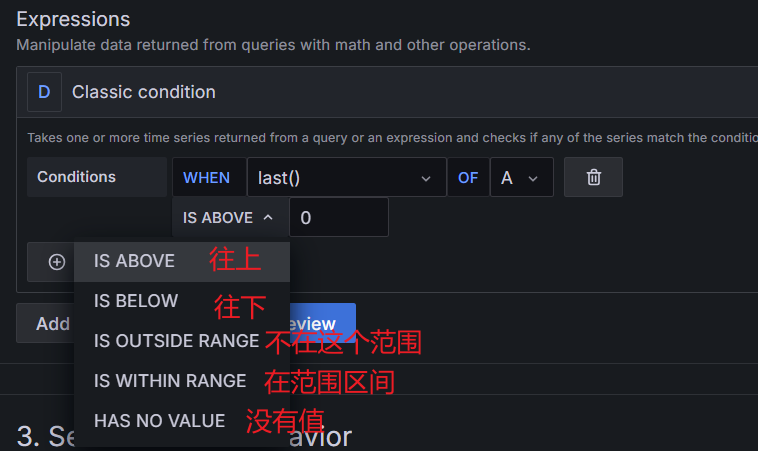
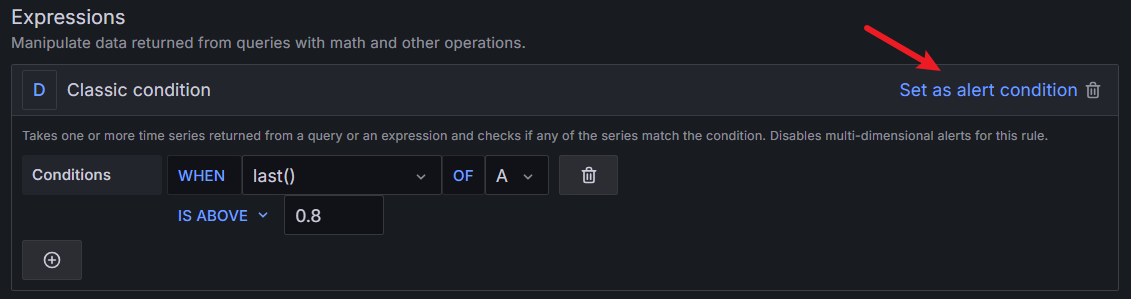
当 cpu 在 1 分钟内的负载大于 0.8 时告警
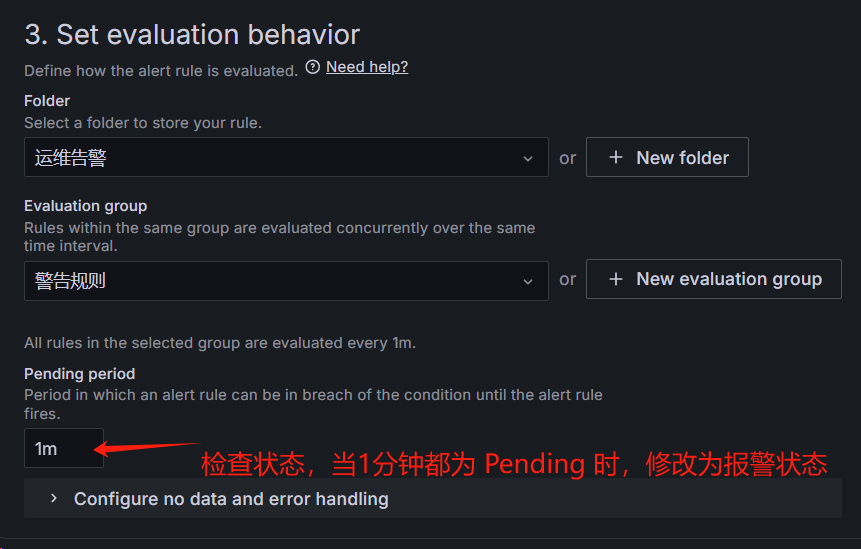
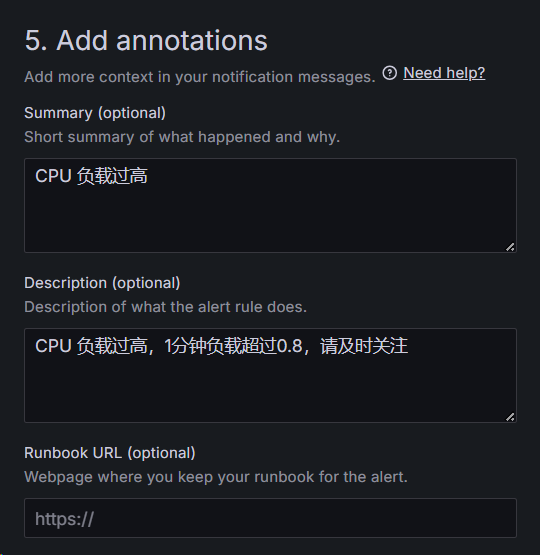
接下来压测 CPU:cat /dev/urandom | gzip -9 > /dev/null