Grafana 数据可视化
Grafana 数据可视化
Grafana是一个监控仪表系统,它是由Grafana Labs公司开发的的一个系统检测工具,它可以大大的帮助我们简化监控的复杂度,我们只需要提供监控的数据,它就可以帮助生成各种可视化仪表,同时它还具有报警功能,可以在系统出现问题的时候发出通知
# 安装和启动
下载 grafana:yum install -y https://dl.grafana.com/enterprise/release/grafana-enterprise-10.4.2-1.x86_64.rpm
yum install grafana-10.4.2-1.x86_64.rpm -y
安装后启动:systemctl start grafana-server
启动报错了
[root@localhost soft]# journalctl -u grafana-server.service -n 50
-- Logs begin at 五 2024-12-20 00:28:20 CST, end at 四 2024-12-19 17:20:35 CST. --
12月 19 17:20:34 localhost.localdomain grafana[30734]: logger=ngalert.migration t=2024-12-19T17:20:34.83176
12月 19 17:20:34 localhost.localdomain grafana[30734]: logger=ngalert.state.manager t=2024-12-19T17:20:34.8
12月 19 17:20:34 localhost.localdomain grafana[30734]: logger=infra.usagestats.collector t=2024-12-19T17:20
12月 19 17:20:34 localhost.localdomain grafana[30734]: logger=server t=2024-12-19T17:20:34.846483039+08:00
12月 19 17:20:34 localhost.localdomain grafana[30734]: Error: ✗ failed to verify pid directory: mkdir /var/
12月 19 17:20:34 localhost.localdomain systemd[1]: grafana-server.service: main process exited, code=exited
12月 19 17:20:34 localhost.localdomain systemd[1]: Failed to start Grafana instance.
12月 19 17:20:34 localhost.localdomain systemd[1]: Unit grafana-server.service entered failed state.
12月 19 17:20:34 localhost.localdomain systemd[1]: grafana-server.service holdoff time over, scheduling res
12月 19 17:20:34 localhost.localdomain systemd[1]: Stopping Grafana instance...
12月 19 17:20:34 localhost.localdomain systemd[1]: Starting Grafana instance...
12月 19 17:20:35 localhost.localdomain grafana[30763]: logger=settings t=2024-12-19T17:20:35.13608298+08:00
12月 19 17:20:35 localhost.localdomain grafana[30763]: logger=settings t=2024-12-19T17:20:35.136566961+08:0
12月 19 17:20:35 localhost.localdomain grafana[30763]: logger=settings t=2024-12-19T17:20:35.136600714+08:0
lines 1-15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
从日志来看,Grafana 服务启动失败的主要原因是以下错误:Error: ✗ failed to verify pid directory: mkdir /var/
表明 Grafana 无法创建或访问 pid 文件所需的目录 /var/run/grafana-server,可能是权限问题或路径不存在
sudo mkdir -p /var/run/grafana-server
sudo chown grafana:grafana /var/run/grafana-server
# 确保 /var 目录没有被意外修改,应该有以下权限
drwxr-xr-x. 21 root root 4096 <日期时间> /var
# 如果权限被更改,修复为
sudo chmod 755 /var
# 如果 /var/run 是临时文件系统(会在重启后清空),可以将 pid 文件位置改为其他永久目录,例如 /var/lib/grafana
vi /usr/lib/systemd/system/grafana-server.service
# 找到以下内容 --pidfile=${PID_FILE_DIR}/grafana-server.pid
# 将 ${PID_FILE_DIR} 替换为 /var/lib/grafana
--pidfile=/var/lib/grafana/grafana-server.pid
sudo systemctl daemon-reload
# 再次启动 grafana 成功了,默认端口为 3000
2
3
4
5
6
7
8
9
10
11
12
13
访问:IP:3000
默认用户名密码:admin/admin
# 整合 Prometheus
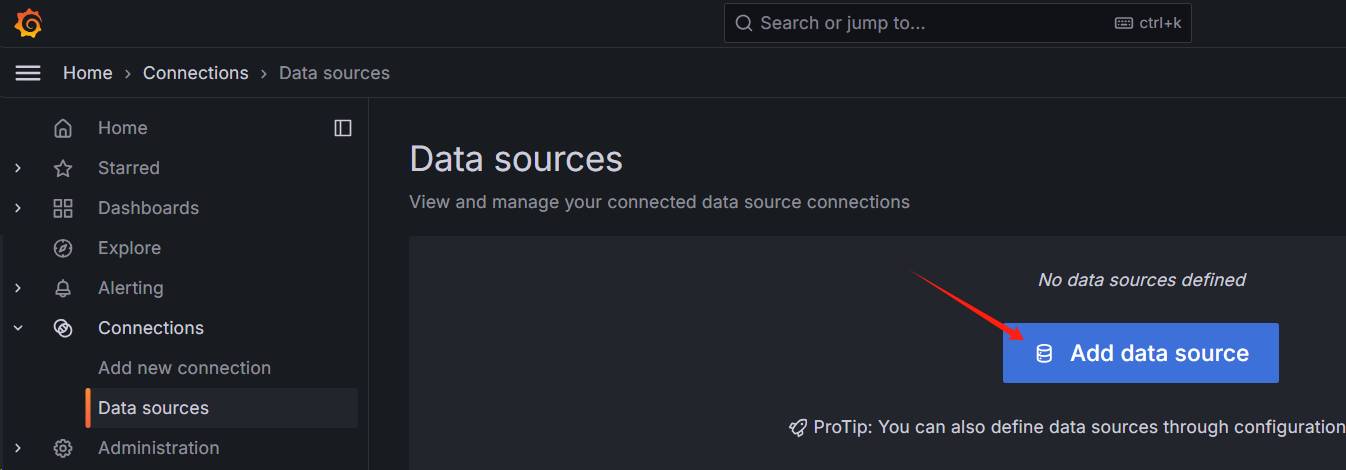
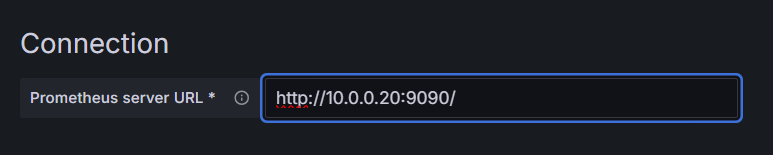
填写 Prometheus 的地址
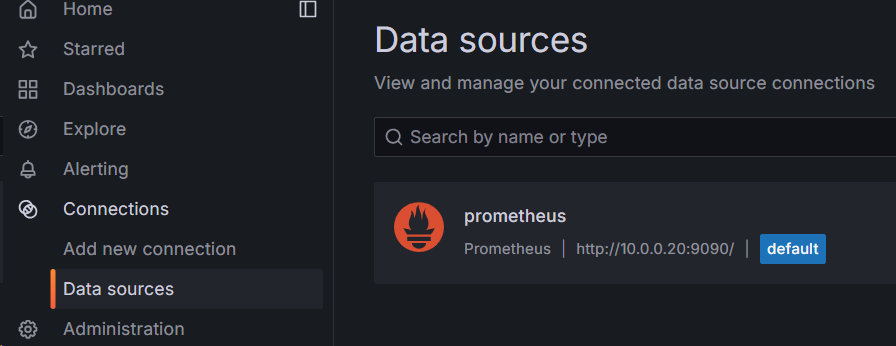
添加后的状态
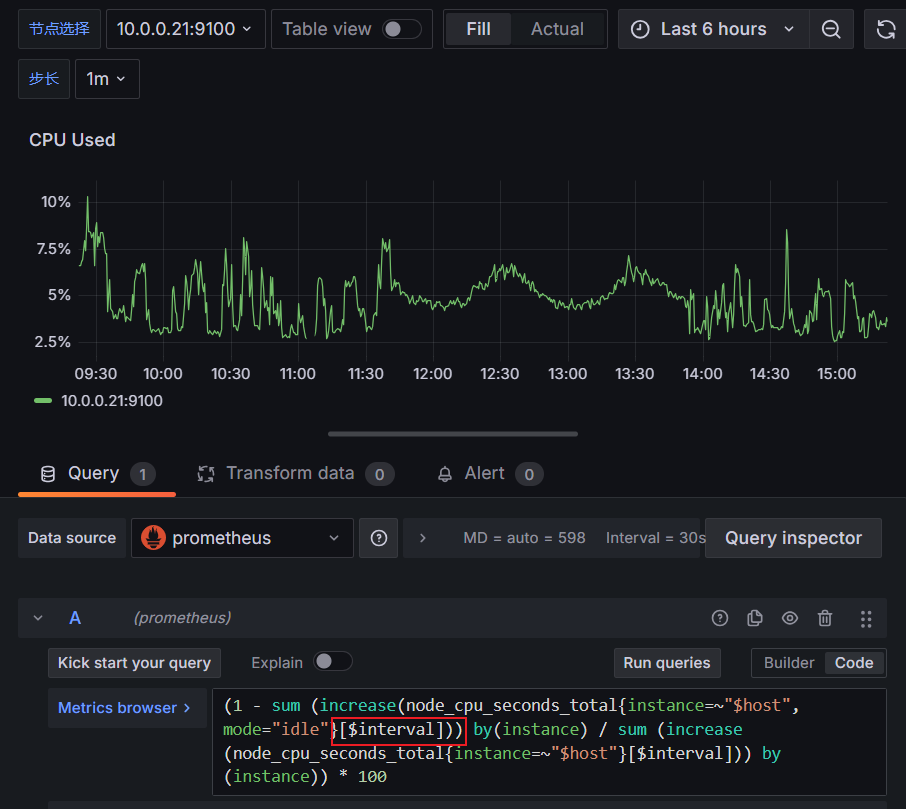
# 实现 CPU 负载监控
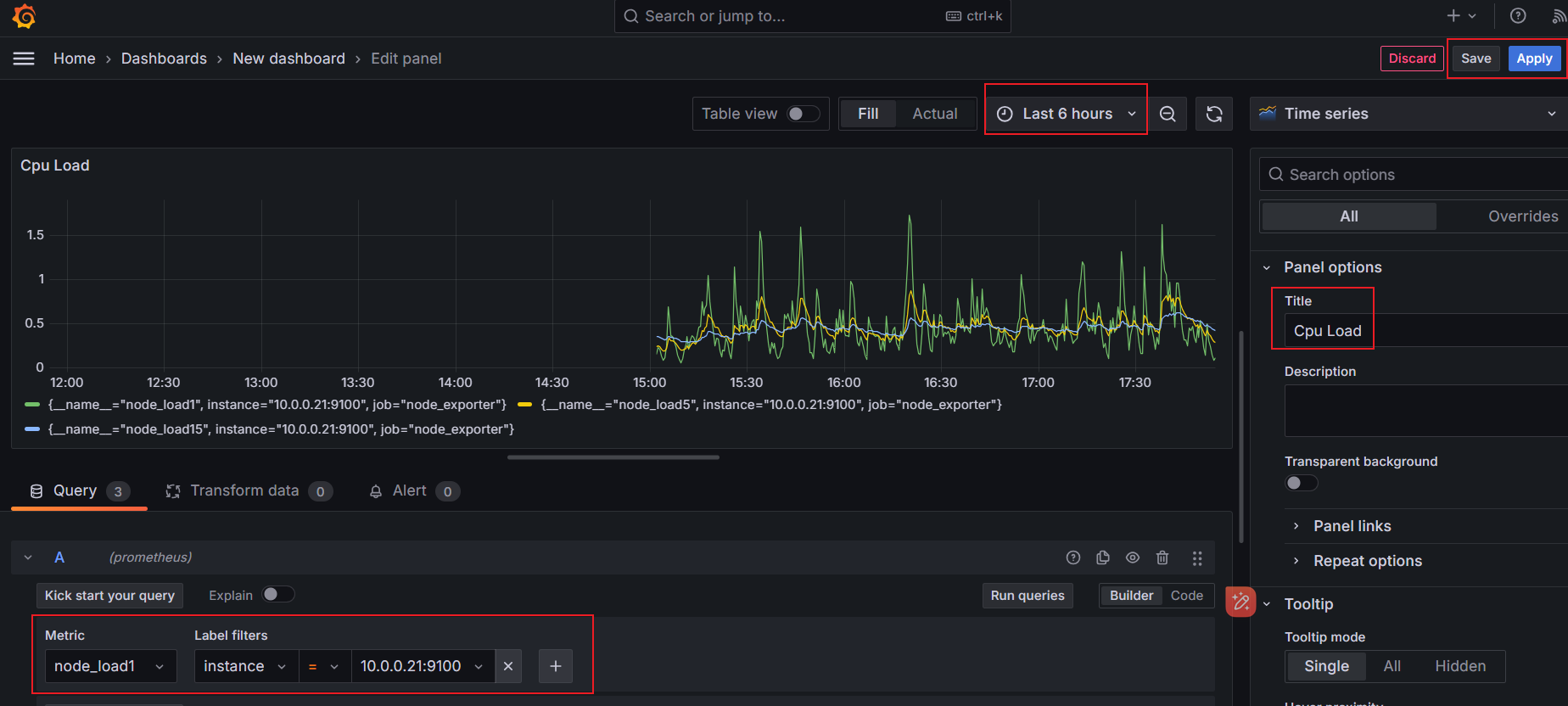
通过自定义的 PromQL 来获取监控数据
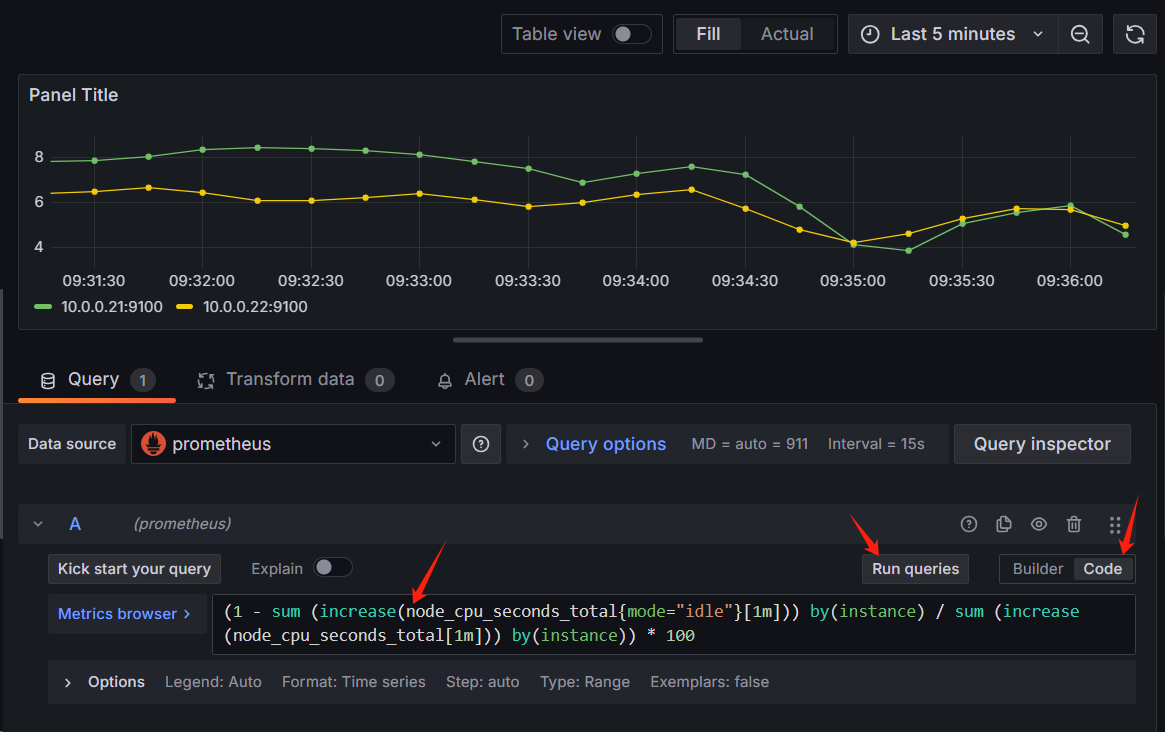 因为可能涉及到我们的主机会比较多,所以集合在一起的话不太直观,所以我们完全可以通过参数来实现各个主机展示各个图标
因为可能涉及到我们的主机会比较多,所以集合在一起的话不太直观,所以我们完全可以通过参数来实现各个主机展示各个图标
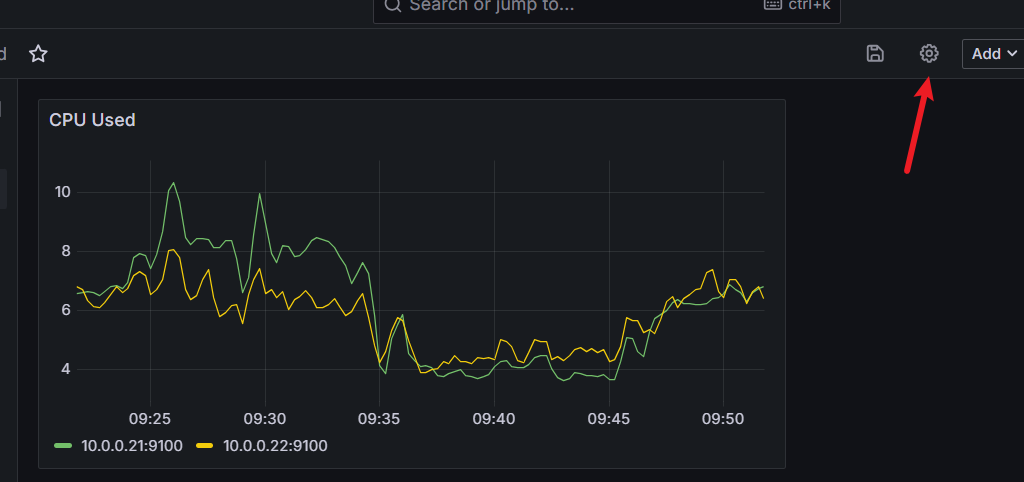
 这里有两种获取主机的方式:
这里有两种获取主机的方式:
1.使用up{job="node_exporter"}过滤主机,然后使用regex正则匹配.*instance="(.*?)".*
2.直接使用函数label_values取标签label_values(up{job="node_exporter"}, instance)
2
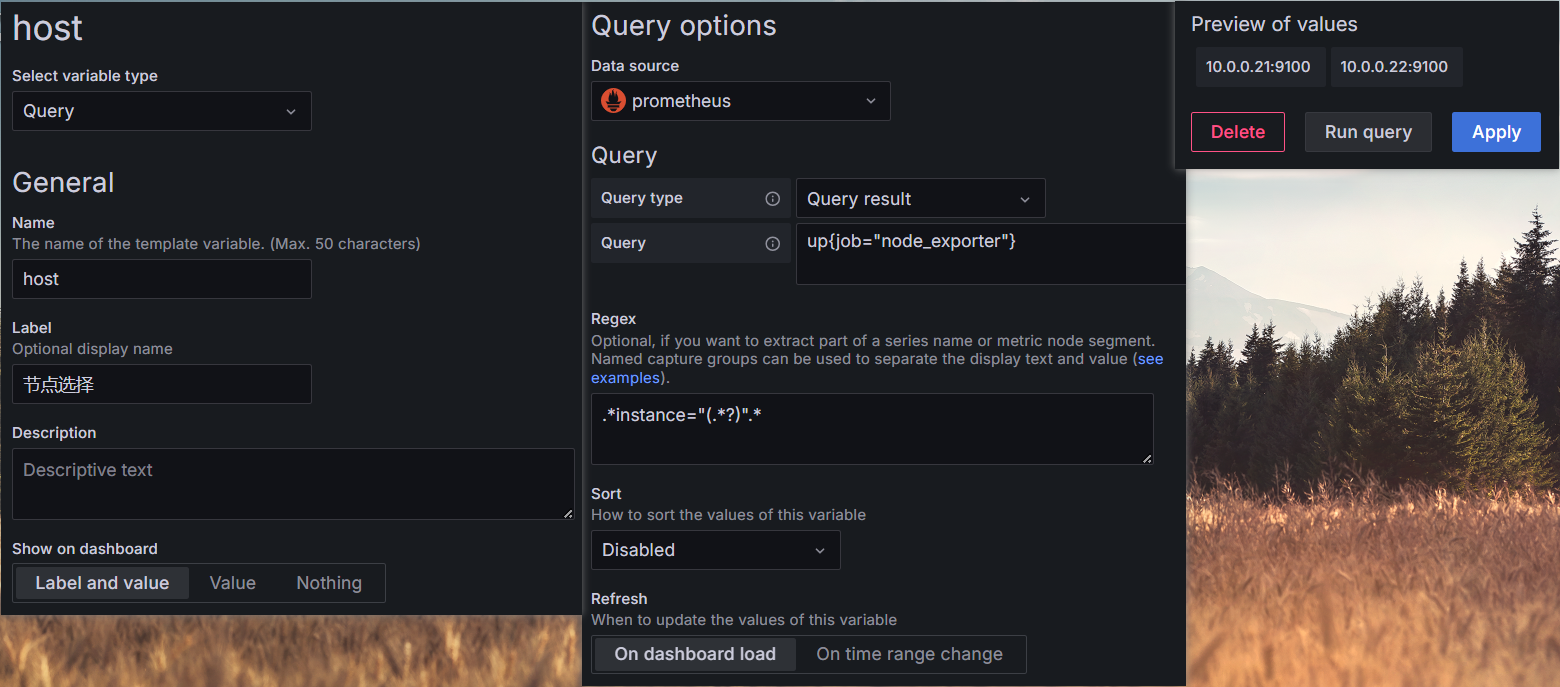
此时选择节点仍然不会生效预期结果
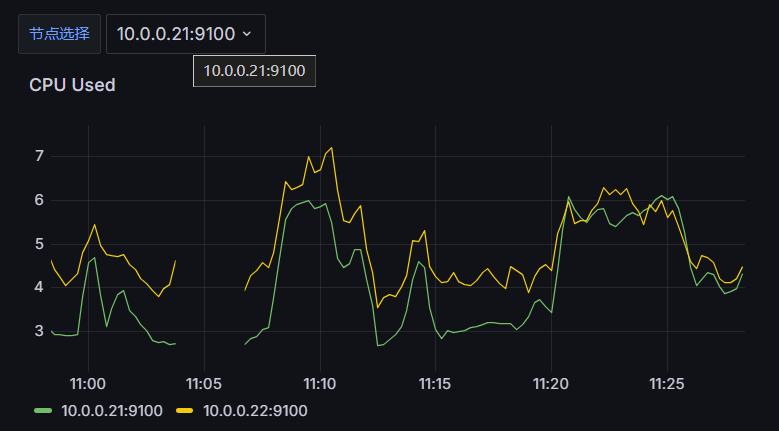
PromQL:(1 - sum (increase(node_cpu_seconds_total{instance=~"$host",mode="idle"}[1m])) by(instance) / sum (increase(node_cpu_seconds_total{instance=~"$host"}[1m])) by(instance)) * 100
当我们把过滤标签替换成变量之后我们上上面选择的是哪儿个它就会给我们把变量传递到PromQL进行查询
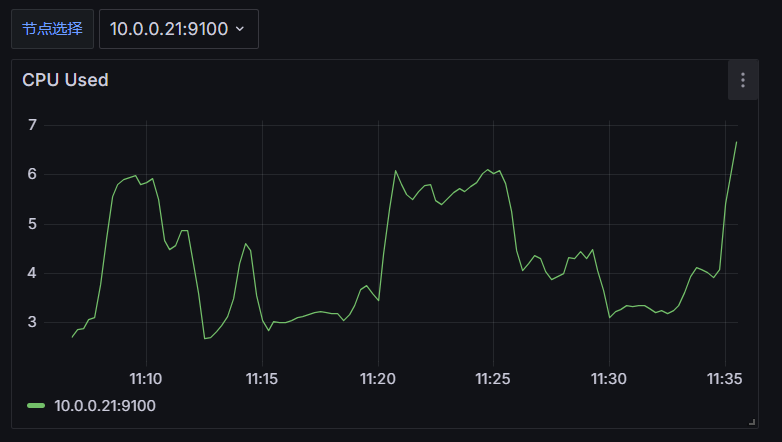 这样我们的参数就替换好了
这样我们的参数就替换好了
添加对时间序列的描述
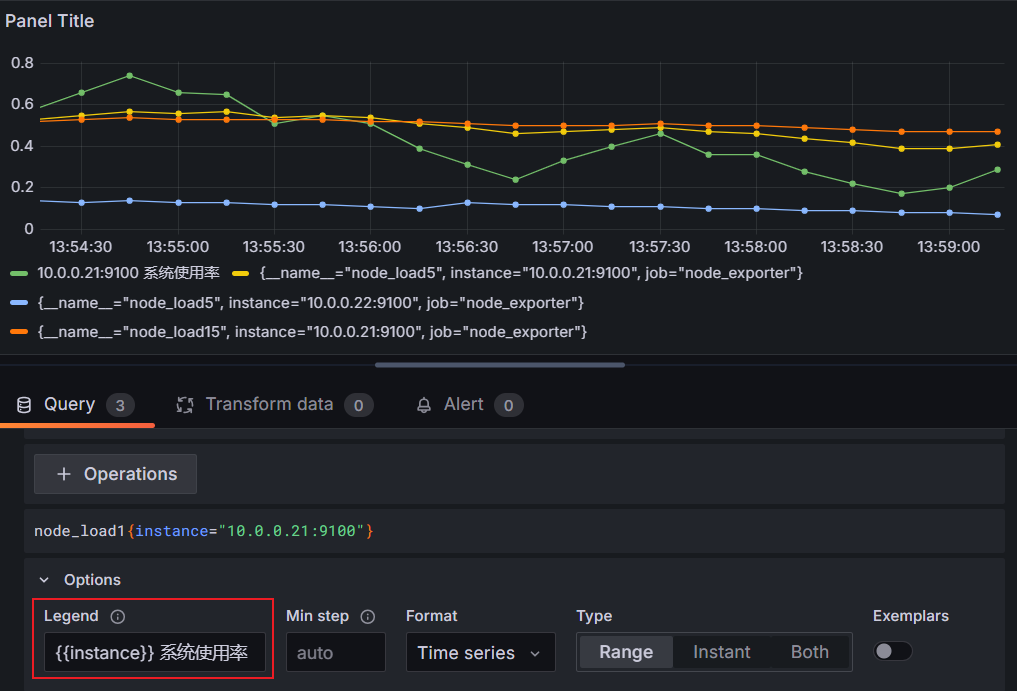 Transform:它支持我们的数据在展示之前多数据进行操作
Transform:它支持我们的数据在展示之前多数据进行操作
这里我们用到了 Rename by regex 来重命名我们的数据
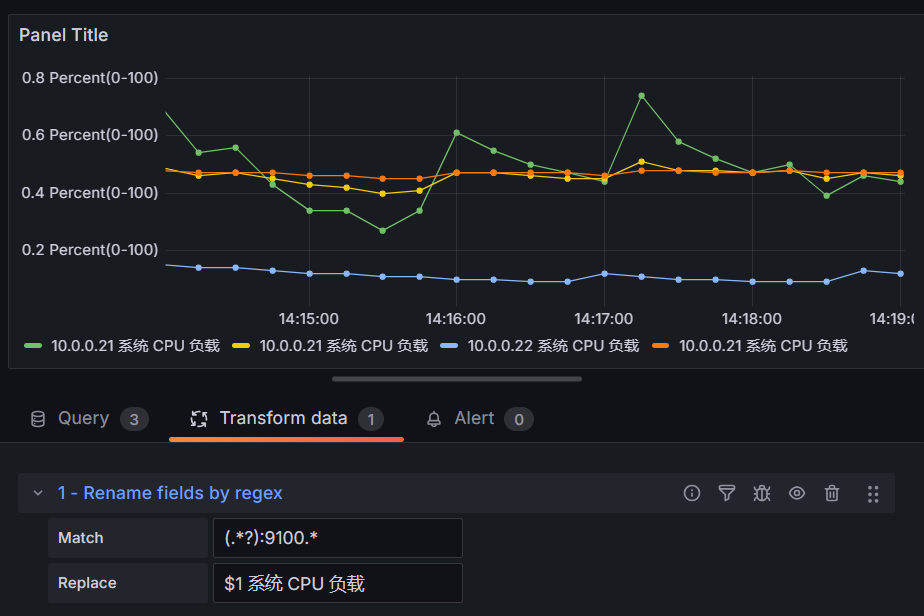 这里主要是我们匹配 :9100 这个数据然后 $1 就是我们的主机名,意思就是他会把匹配到的 9100 的所有的值全部替换成 $1 也就是我们的主机名
这里主要是我们匹配 :9100 这个数据然后 $1 就是我们的主机名,意思就是他会把匹配到的 9100 的所有的值全部替换成 $1 也就是我们的主机名
我们都知道我们在计算的时候其实 cpu 的使用率都乘 100 了,那么我们其实还可以做一下配置
在右侧选择 Standard options ---> Unit ---> Misc ---> Percent(0-100)(百分比) Decimals (保留小数的最小位数)
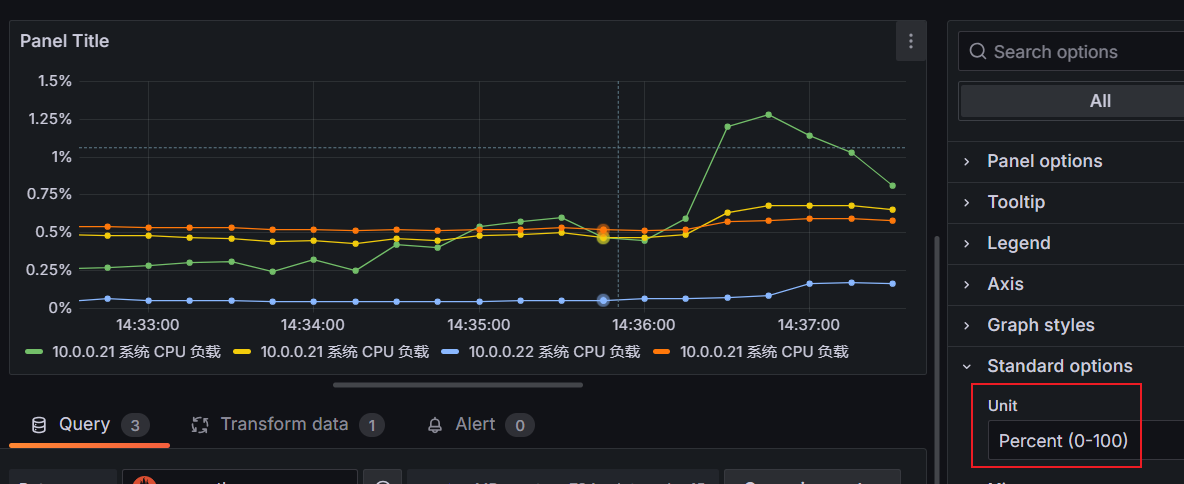
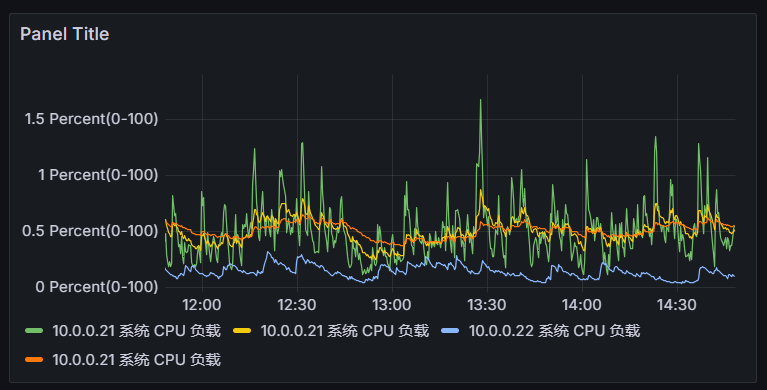 在这里面还有一个问题,就是我们在执行图形的查询的时候区间向量都是一分钟,但是有的时候我们需要查询的不只是一分钟,所以我们需要把这个数值改成参数的形式,和host类似的写法
在这里面还有一个问题,就是我们在执行图形的查询的时候区间向量都是一分钟,但是有的时候我们需要查询的不只是一分钟,所以我们需要把这个数值改成参数的形式,和host类似的写法
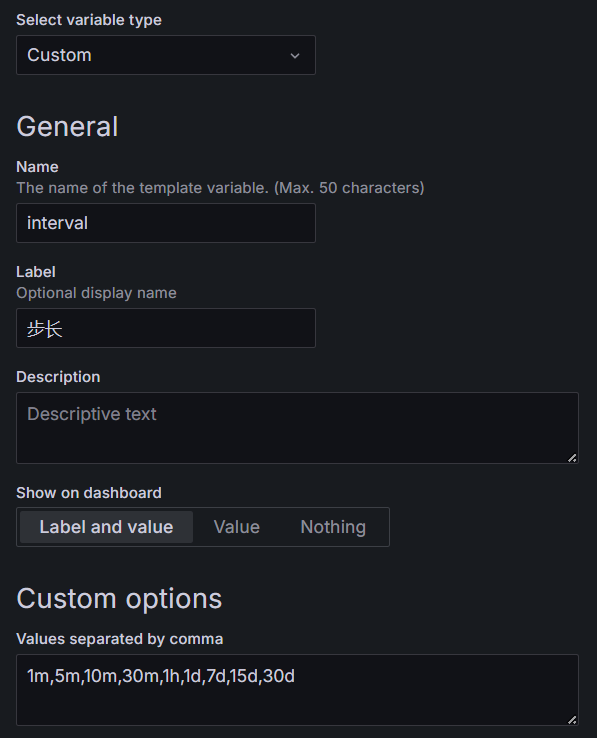 遵循host的替换规则,我们也把interval替换上去,然后上图就是替换好的一个样子了
遵循host的替换规则,我们也把interval替换上去,然后上图就是替换好的一个样子了
# 监控模型
除了用默认的时间序列面板外,还有许多其他的面板
# 表格面板
表格面板可视化非常的灵活,支持时间序列和表格和原始 json 数据的多种样式,此面板还提供日期格式,值格式和着色选项
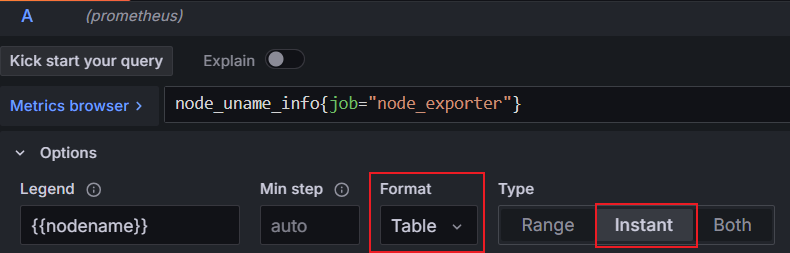
接下来我们演示一下统计服务器资源为例使用表格面板进行说明,在 Dashboard 中添加一个空的 Panel 面板进入面板后选择 Table 面板
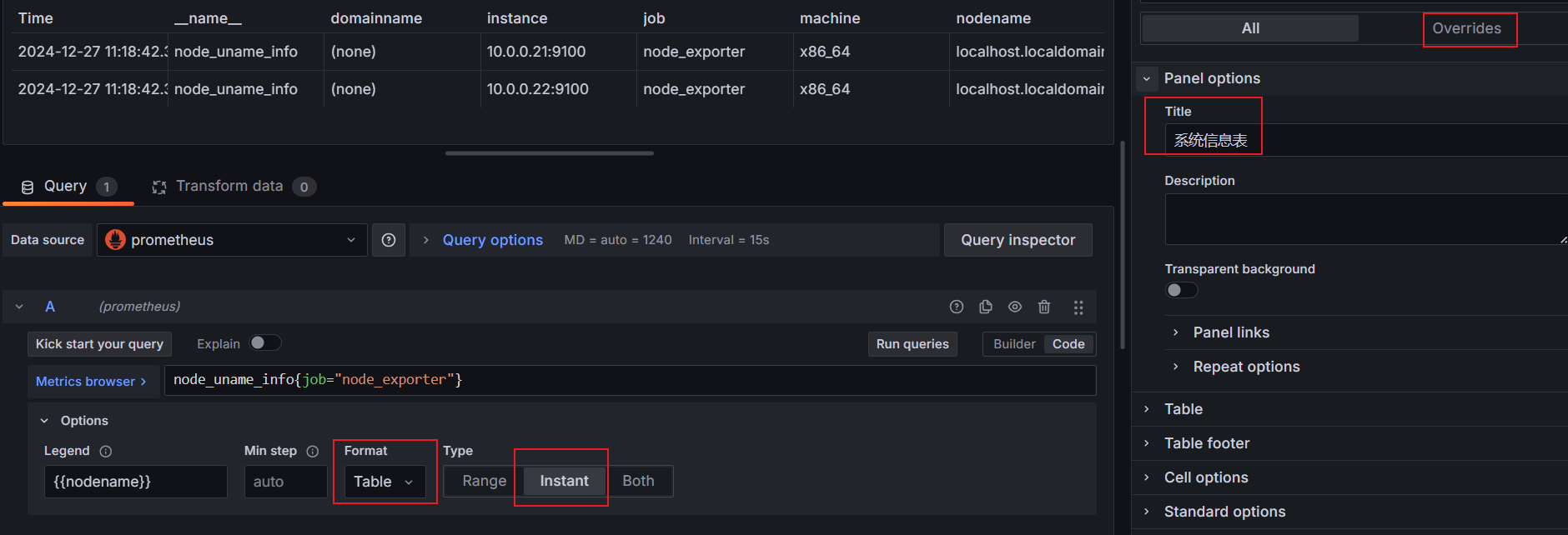
- 在右上角选择面板类型, (1) 选择 Table
- 修改左下 Query 面板中, (2) 将 Format 修改为 Table, (3) Type 修改为 Instant
- 在面板的展示区, 将以表格形式出现。点击 (4) 刷新按钮, 立即更新查询内容。尤其是在每次修改后, 都建议点一下
- 在右边 (5) All 配置区, 可以配置界面的基本信息
- 在右边 (6) Overrides 配置区, 针对表格字段进行 高级配置
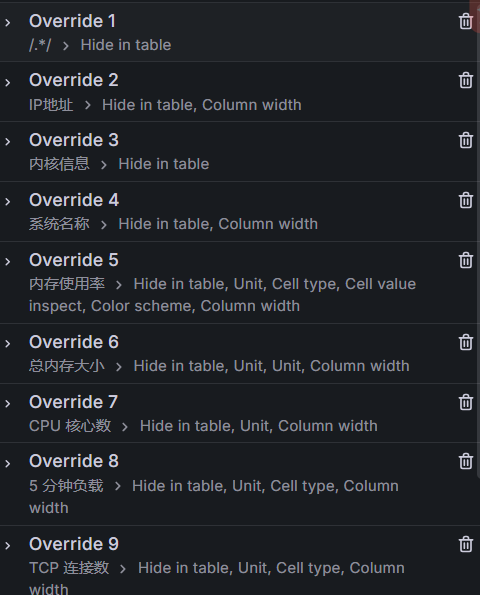
字段高级配置
进行字段的展示筛选, 有两种方法。就个人而言, 更喜欢白名单方法
- 白名单方法:即 (1) 隐藏所有字段, (2) 在展示需要字段
- 黑名单方法:即直接隐藏不需要的字段
先来看下最终效果

PromQL
node_uname_info{job="node_exporter"}
(node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Buffers_bytes - node_memory_Cached_bytes) / node_memory_MemTotal_bytes * 100
node_memory_MemTotal_bytes / 1024 / 1024
count(count(node_cpu_seconds_total) by (instance, cpu)) by (instance)
node_load5
node_netstat_Tcp_CurrEstab
rate(node_network_transmit_bytes_total{device="eno16777736"}[1m]) * 8 / 1e6
rate(node_network_receive_bytes_total{device="eno16777736"}[1m]) * 8 / 1e6
2
3
4
5
6
7
8
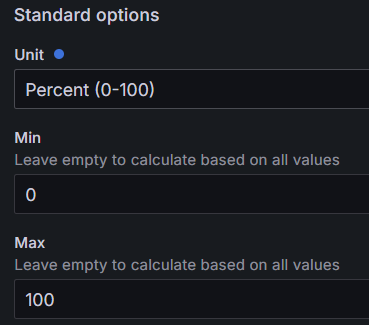
 当时遇到的问题,在使用 LED 装饰内存使用率图标时,发现百分比和 LED 灯的数量对不上,60% 时 LED 就全亮了,后来发现需要在 ALL 全局配置中设置 Percent 的最大值 0 和最小值 100
当时遇到的问题,在使用 LED 装饰内存使用率图标时,发现百分比和 LED 灯的数量对不上,60% 时 LED 就全亮了,后来发现需要在 ALL 全局配置中设置 Percent 的最大值 0 和最小值 100
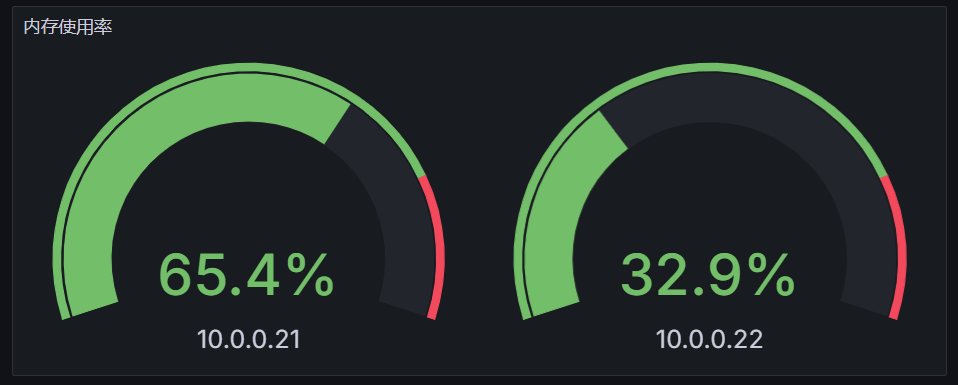
# 仪表盘(Gauge)
如果想展示最大值与最小值相关的数据,我们可以选择使用仪表盘面板,比如我们用一个仪表盘面板来展示内存使用率
PromQL:100 * (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes))
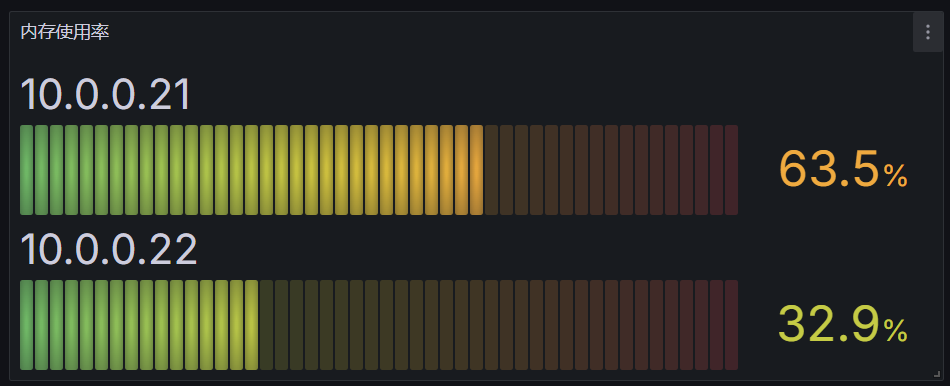
除了上面瞄准的仪表盘外,还有条形式仪表盘,该面板可以显示一个或多个条形仪表,同样我们可以用来展示CPU使用率内存使用率等
Bar Gauge
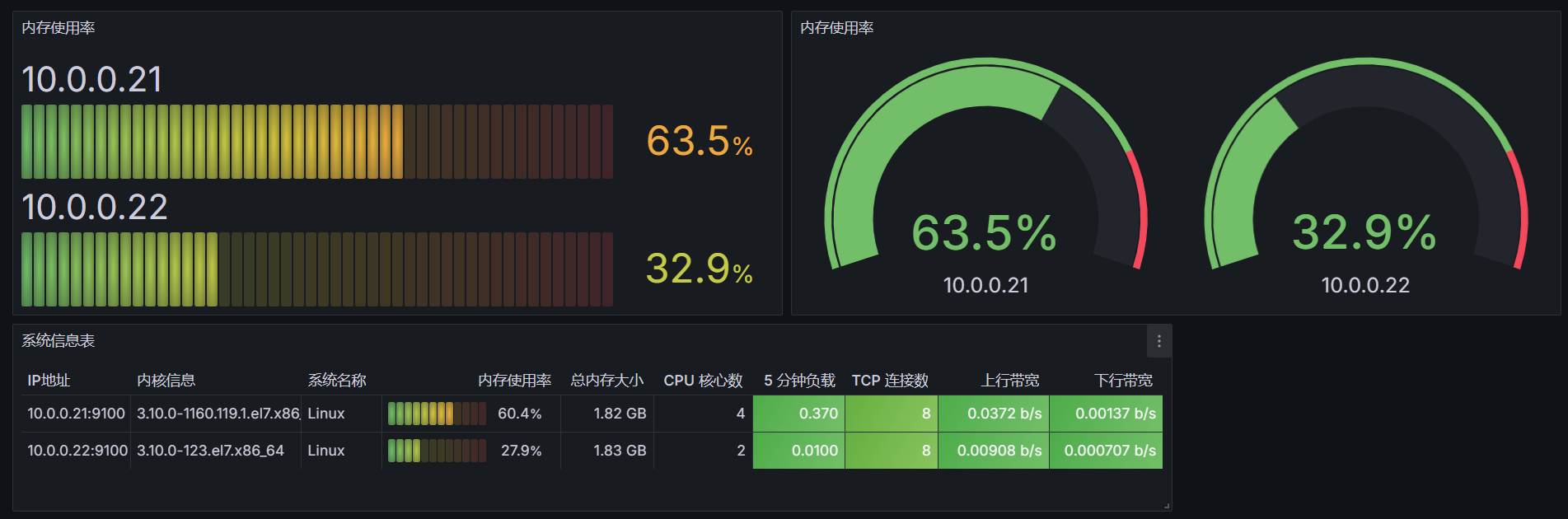
 整体效果看一下(自行排版)
整体效果看一下(自行排版)
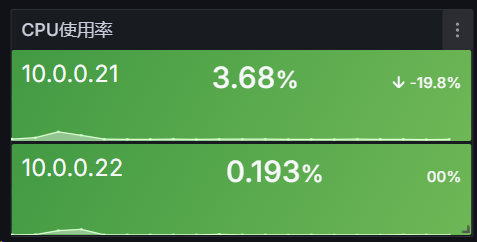
# 9.4.3 统计面板(Stat)
统计面板可以用于显示一个大的统计值和一个可选的背景色,我们可以使用阈值来控制背景色或者颜色值,接下来我们使用该面板来统计几个监控数据,比如节点运行时间,CPU核心数,总内存大小等等
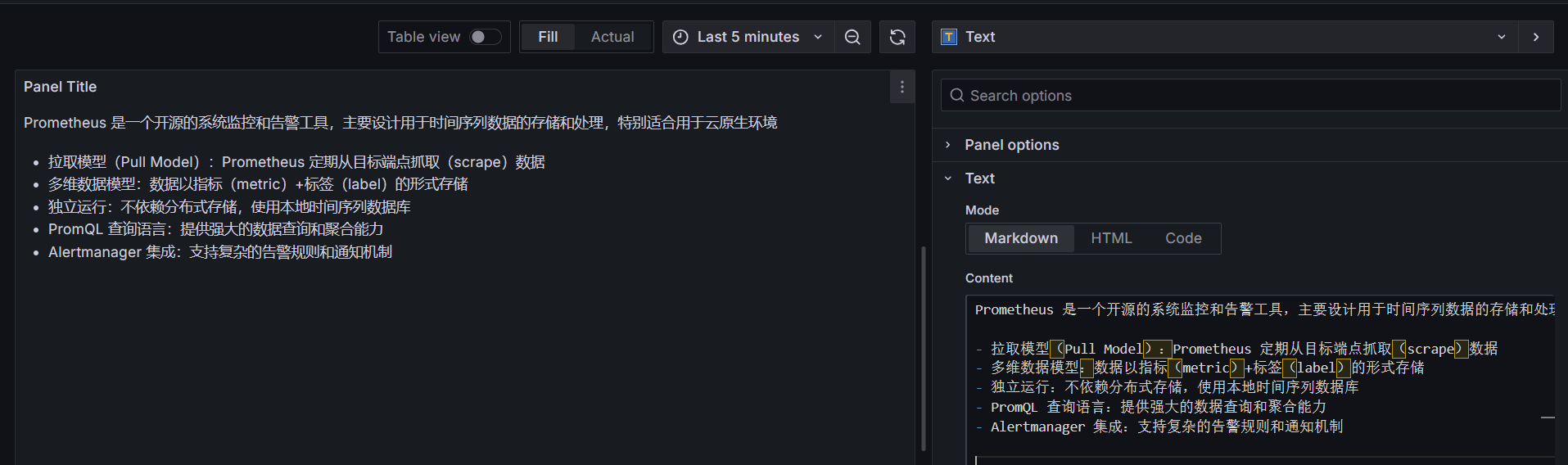
# 文本面板(Text)
该面板不需要查询语句,直接用来展示文本信息,而且是支持 Markdown 和 HTML 两种格式,这就为我们提供了很大的定制灵活性
文本面板的使用非常简单,直接选择使用 Markdown 还是 HTML 来设置文本样式即可,然后在面板编辑器的文本框中输入内容即可。比如很多公司业务太大太多,需要监控的 Dashboard 非常多,操作管理起来非常麻烦,这个时候我们就可以使用文本面板来做一个导航页面进行归类
整体看一下
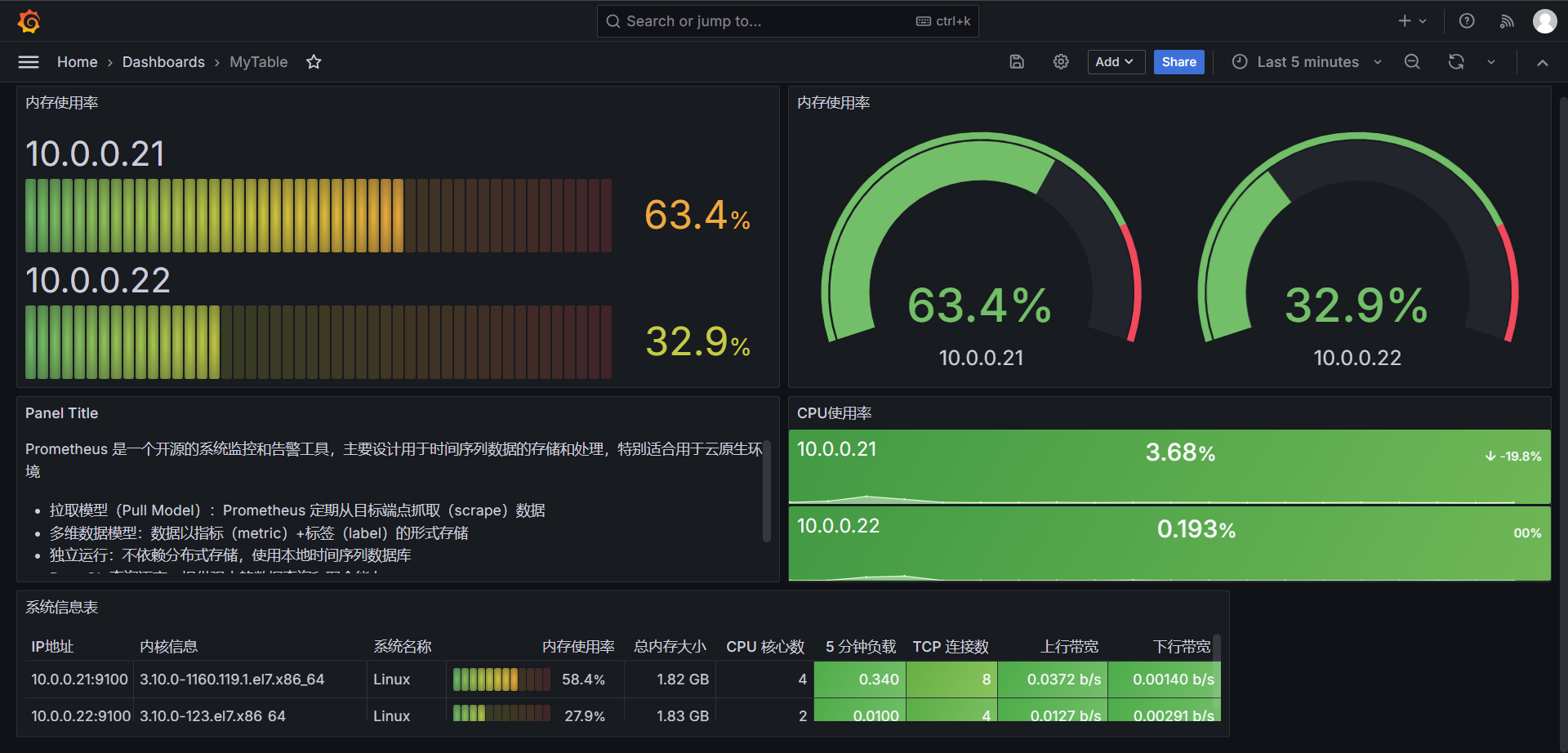
当然了这里支持 HTML 与 MarkDown 的语法,我这里使用的是 MarkDown 语法来写的一个简单的页面
# 通过模板的方式实现监控
https://grafana.com/grafana/dashboards/
在官网下载 JSON 或是通过 Dashboard ID 导入
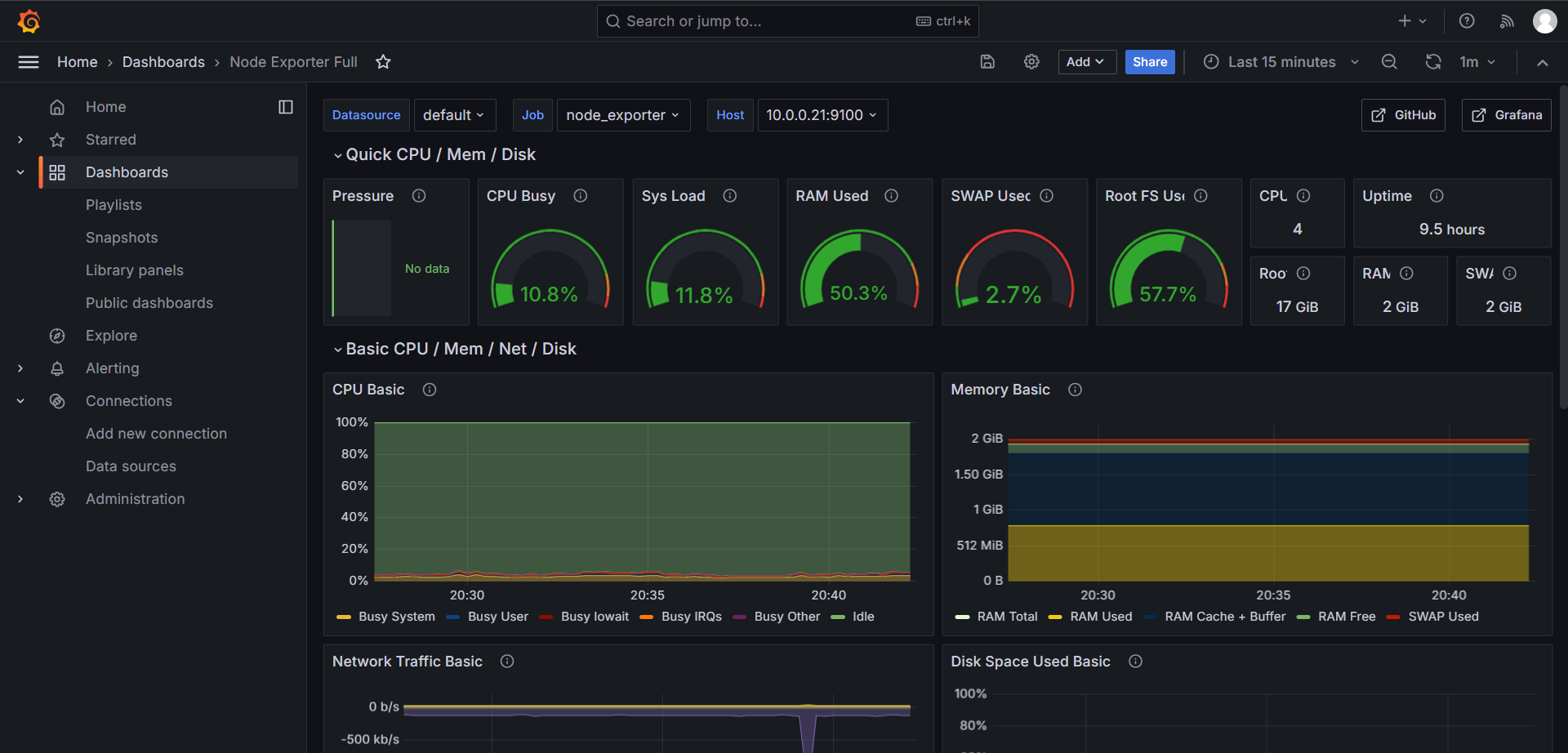
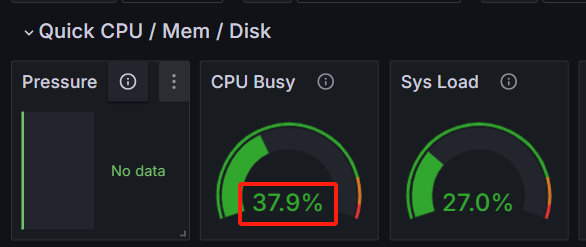
使用 cat /dev/urandom | gzip -9 > /dev/null 压测系统,观察 CPU 变化
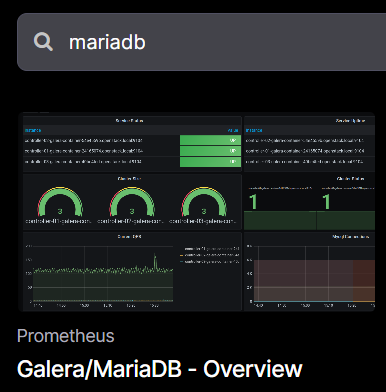
# 通过模板的方式监控 mariadb